OCaml で正規表現エンジンを作る [OCaml]
結構前にブックマークして後でちゃんと読もうと思ってた「Regular Expression Matching Can Be Simple And Fast」という記事 [1] があるのだけど、それを参考にして OCaml で正規表現エンジンを作ってみました。
type state =
| Char of char * state ref
| Split of state ref * state ref
| Match
type frag = {nfa: state; danglings: state ref list}
let post_of_regex regex =
let rec expr = parser
| [< c = conc; t = expr_tail >] -> c ^ t
and expr_tail = parser
| [< ''|'; c = conc; t = expr_tail >] -> c ^ "|" ^ t
| [< >] -> ""
and conc = parser
| [< r = rept; t = conc_tail >] -> r ^ t
and conc_tail = parser
| [< r = rept; t = conc_tail >] -> r ^ "." ^ t
| [< >] -> ""
and rept = parser
| [< a = atom; t = rept_tail >] -> a ^ t
and rept_tail = parser
| [< ''?' >] -> "?"
| [< ''*' >] -> "*"
| [< ''+' >] -> "+"
| [< >] -> ""
and atom = parser
| [< ''('; e = expr; '')' >] -> e
| [< ''a'..'z' as c>] -> String.make 1 c
in
expr (Stream.of_string regex)
let patch l s = List.iter (fun o -> o := s) l
let rec nfa_of_post' frags = parser
| [<''.'; strm>] ->
let e2::e1::rest = frags in
let frags = {nfa = e1.nfa; danglings = e2.danglings}::rest in
patch (e1.danglings) e2.nfa;
nfa_of_post' frags strm
| [<''|'; strm>] ->
let e2::e1::rest = frags in
let out1 = ref e1.nfa in
let out2 = ref e2.nfa in
let nfa = Split (out1, out2) in
let danglings = e1.danglings @ e2.danglings in
let frags = {nfa = nfa; danglings = danglings}::rest in
nfa_of_post' frags strm
| [<''?'; strm>] ->
let e::rest = frags in
let out1 = ref e.nfa in
let out2 = ref Match in
let nfa = Split (out1, out2) in
let danglings = out2 :: e.danglings in
let frags = {nfa = nfa; danglings = danglings}::rest in
nfa_of_post' frags strm
| [<''*'; strm>] ->
let e::rest = frags in
let out1 = ref e.nfa in
let out2 = ref Match in
let nfa = Split (out1, out2) in
let frags = {nfa = nfa; danglings = [out2]}::rest in
patch (e.danglings) nfa;
nfa_of_post' frags strm
| [<''+'; strm>] ->
let e::rest = frags in
let out1 = ref e.nfa in
let out2 = ref Match in
let nfa = Split (out1, out2) in
let frags = {nfa = e.nfa; danglings = [out2]}::rest in
patch (e.danglings) nfa;
nfa_of_post' frags strm
| [<'c; strm>] ->
let out = ref Match in
let nfa = Char (c, out) in
let frags = {nfa = nfa; danglings = [out]}::frags in
nfa_of_post' frags strm
| [< >] -> (List.hd frags).nfa
let nfa_of_post post =
nfa_of_post' [] (Stream.of_string post)
let rec add_state state states =
if List.mem state states then states
else
match state with
| Split (out1, out2) -> add_state !out1 (add_state !out2 states)
| _ -> state::states
let step c states =
let rec filter acc = function
| Char (c', out) -> if c = c' then (add_state !out acc) else acc
| _ -> acc
in
List.fold_left filter [] states
let rec matching states = parser
| [<'c; strm>] -> matching (step c states) strm
| [< >] -> states
let match_regex regex s =
let post = post_of_regex regex in
let start = nfa_of_post post in
let result = matching (add_state start []) (Stream.of_string s) in
List.mem Match result
let _ =
let regex = Sys.argv.(1) in
for i = 2 to pred (Array.length Sys.argv) do
if match_regex regex Sys.argv.(i)
then print_endline Sys.argv.(i)
done
まず post_of_regex 関数で正規表現を後置記法に変換します。これはドットを「連結」の意味に使うもので、たとえば ab?cd は ab?.c.d. になって a(bc)+d は abc.+.d. になります。
nfa_of_post 関数でその後置記法正規表現から NFA という構造に変換します。これは [1] の図を参照。NFA を表現するデータ型を state 型として定義しています。変換の過程で NFA の断片とその断片中の行き先がまだ決まっていない矢印をセットで扱うために frag 型を定義しています。patch 関数でそうした矢印の先を行き先に結びつけます。
そのようにしてできた NFA を使って実際にマッチングを行うのが matching 関数で、これは入力の各文字について期待される文字とマッチしているかどうかを確認していくのですが、NFA が分岐する場合は分岐した状態をパラレルに保持しながらステップを進めていきます。
さて [1] の記事の強く主張するところは、このやり方は Perl をはじめとする多くのスクリプト言語で採用されているものよりもずっと速い(というか難しい正規表現でも速度が劣化しにくい)、ということなのだけど、この正規表現エンジンはどうだろうか。というわけで [1] の記事で使われているのと同じスクリプトを使って計測してグラフにしてみました。
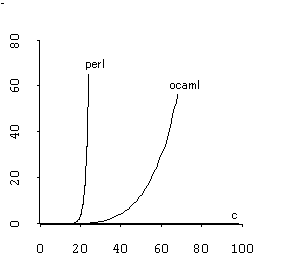
グラフ中の perl が Perl で、私の作ったのが ocaml で、元記事のプログラムが c です。Perl 程ではないけど元記事のプログラムより断然性能劣化が早いという残念な結果に。んーなんかまずいことをしてしまってる部分があるんだろうなあ。とりあえずちゃんと動く正規表現エンジンが書けたというだけで満足気味なので今はもうこれでいいや。
ところで [1] の中ごろのグラフを見ると私の好きな Tcl は実は正規表現がかなり良い結果だということがわかります。The Computer Language Benchmarks Game というサイトで普通 Tcl は軒並み下位なんですが regex-dna という問題だけはかなりの上位 [2] だったのを以前見て疑問に思ってたんですが、そういうわけだったのかと。
[1] http://swtch.com/~rsc/regexp/regexp1.html
[2] http://shootout.alioth.debian.org/debian/benchmark.php?test=regexdna&lang=all
ether さん

-
nice! 34
記事 322
テーマ パソコン・インターネット
プロフィール
ブログを紹介する
--




コメント 0