JIRAやConfluenceのアドオンをGoogle App Engineで動かす [Java]
https://bitbucket.org/tkob/acspring-gcloud-quickstart
いまAtlassianのクラウド製品のアドオンを作るときはAtlassian Connectという作法に従って、Webアプリケーション(Atlassian製品の外で動作する)をアドオンとしてつくって製品と連携するということになっています。それをJavaで作るときはAtlassian Connect Spring BootというSpring BootベースのフレームワークがAtlassian公式として公開されています。
https://bitbucket.org/atlassian/atlassian-connect-spring-boot
JIRAアドオンを気軽に作ろうと思うとこれを動かすためのサーバーを見つけないといけません。ここで無料のサーバーで動かしたい…と思うと、今だとGCPのフリーティアーが候補になると思います。
1つの候補はCompute Engineのf1-microインスタンスを使うことですが、ここで問題になるのはAtlassian ConnectではHTTPS通信を必須としていることで、GCEの場合だと追加でドメイン取得が必要となります。
もう1つの可能性はApp Engineのスタンダード環境を使うことですが、(1) Spring BootはJava8以降が要件であること (2) フリーティアーで使えるストレージはCloud Datastoreしかない(Atlassian Connect Spring BootはSpring Dataを使ってインストール先ホストを保存するのだが、Cloud Datastore用のSpring Dataがない)という点が問題でした(appspot.comドメインはHTTPSが使えます)。
(1)については最近までGAEスタンダード環境ではJava7のみだったのが最近Java8対応したことで解消されました。(2)については自分で作ることで解消しました。1つ前の記事のSpring Data Google Cloud Datastoreがそれです。
手順にしたがってMavenアーキタイプからプロジェクトを作るとサンプルアプリが動くようになっていて、このアプリはJIRAから課題を取得してDatastoreに保存し、それを集計して表示するということをやっています(なお、Datastoreは集約関数が利用できないため本来こうした集計には向いていません。使い方の例としてそのようにしています)。
Spring Data Google Cloud Datastoreを作った。 [Java]
https://github.com/tkob/spring-data-gclouddatastore
その名の通りSpring Dataの作法でGoogle Cloud DatastoreのデータをCRUDするものです。クエリメソッド(インターフェイスにfindByFooOrderByBarなどメソッド定義するとそのメソッド名に従った実装を提供する機能)にも対応しています。
リモート参照を含むNetBeansのnbmファイルをオフライン化するツール [Java]
NetBeansのプラグインモジュールをオフライン環境下でインストールするには nbmファイルをダウンロードしてくればよいが、 このnbmファイルがリモートのファイルへの参照を含んでいる場合、 単独ではインストールに失敗する。
nbmファイルは実態としてはZIPファイルだが、 その中に.externalというファイルが含まれている場合、 NetBeansが.externalの中に書かれたURLからダウンロードして置き換える仕組みになっているからだ。
一方で、この.externalを置き換えたZIPファイルをあらかじめ用意しておけば、 そのようなnbmファイルでもオフラインでインストールできる。 例えば下記のサイトでそのような方法が紹介されている。
NetBeans80にofflineでJUnitをインストール
しかしこれを手動で行うのは面倒だ。ということで自動で行うツールを作った。
nbmtools: https://github.com/tkob/nbmtools
これを使うと上掲の記事の作業は次のようにすればよい。
なお作ってはみたものの.externalを含むnbmファイルはあまり多くない気もしている。
技術的に特筆すべきことはないが、ScalaとJavaの半々でコーディングし、 テストのためにYokohamaUnitをドッグフーディングしている。 とてもひさしぶりにScalaを書いた。
JCUnitのテストケースジェネレータを切り出して使う [Java]
JCUnit はJUnitの(サードパーティーの)テストランナーの1つで、 テストの入力となるフィールドにアノテーションをつけておくと、 そのアノテーションを元にしてPairwise法を使ってテストデータを自動生成して実行してくれる。
それはそれで便利なのだが、 今回はJCUnitのPairwiseのアルゴリズムを JCUnitのテストランナー経由ではなくて直接切り出して使いたいと思ったので、 その方法を調べた。
テストケースジェネレータとなるのはTupleGenerator型のオブジェクトである。 TupleGenerator.Builderのfluentなコンストラクタでオブジェクトを作る。
IPO2TupleGeneratorは生成されるTupleGeneratorの実装で、 IPOというのはPairwiseのアルゴリズムの一種のようだ。
ContaraintManagerは変数の組み合わせの制約を指定するためのもののようだが、 今回は何も制約をつけないのでNullConstraintManagerを与えている。
Factorsはテストケースの元となる一連の変数(Factor)の集まりである。 Factorは変数名と変数がとりうる値(level)から成る。
ParamはTupleGeneratorの実装固有のパラメタである。 ここでは何も指定しない(デフォルト)ので空の配列を与えている。
このParamというクラスは実際にはアノテーションクラスで、 普通はJUnitテストクラスに書かれたアノテーションがそのまま来るようだ。 もし今回のような使用方法でParamを指定するとしたら、 ちょっとまどろっこしい書き方をすることになると思う。
TupleGeneratorはIterable<Tuple>を継承しているので、 ここではforEachメソッドで生成結果を取得している。 TupleはMap<String, Object>を継承していて、キーが変数名、値が変数の値となる。
上記のコードの実行結果は次のようになる。
2つの値を持つ変数3つの組み合わせは単純に積を取ると8通りとなるが、 ここでは4通りのみ生成されている。 その一方で、任意の2つの変数の組み合わせはすべて登場するようになっている。
JavaでVisitorのメソッドのthrows節になんと書くべきか [Java]
Javaでヘテロなリスト、たとえばIntegerかStringのどちらかが入るリストを作っておきたいとする。 これをちゃんと静的に型付けされるように書くとしたらJavaではVisitorを使うしかない。
interface IntegerOrString {
void accept(IntegerOrStringVisitor visitor);
}
class I implements IntegerOrString {
private Integer integer;
public I(Integer integer) { this.integer = integer; }
public void accept(IntegerOrStringVisitor visitor) {
visitor.visitInteger(integer);
}
}
class S implements IntegerOrString {
private String string;
public S(String string) { this.string = string; }
public void accept(IntegerOrStringVisitor visitor) {
visitor.visitString(string);
}
}
interface IntegerOrStringVisitor {
void visitInteger(Integer integer);
void visitString(String string);
}
これを使うときはたとえば次のようなコードを書く。
public class Main {
public static void main(String[] args) {
List<IntegerOrString> list = new ArrayList<IntegerOrString>();
list.add(new I(123));
list.add(new S("hello"));
for (IntegerOrString e : list) {
e.accept(new IntegerOrStringVisitor(){
public void visitInteger(Integer integer) {
/* 整数だった時の処理 */
System.out.println(integer + 1);
}
public void visitString(String string) {
/* 文字列だった時の処理 */
System.out.println(string.toUpperCase());
}
});
}
}
}
ここまでは(Javaの冗長さ以外は)なにも問題ないと思う。 ところでこのリストに対して行いたい処理がチェック例外を投げる処理だったらどうするか。 例えば出力先が標準出力でなくてファイルだったらIOExceptionをどうにかしないといけない。
IOExceptionをmainで捕捉することにすると、 コンパイルを通すためにはまず匿名クラスのvisitIntegerとvisitStringにthrows IOExceptionと書かないといけない。
しかし継承・実装元が投げると宣言していないチェック例外を継承・実装先クラスで投げることはできないから、 IntegerOrStringVisitorの同名メソッドでもthrows IOExceptionと書かないといけない。 IとSのacceptメソッドでそれらのメソッドを呼んでいるからそこにもthrows IOException、IとSの実装元であるIntegerOrStringクラスのacceptメソッドも同様にthrows IOExceptionをつける。
だけどこれは明らかにおかしい。IntegerOrStringというデータ型は、そのデータにどのような操作がなされうるかとは独立に定義されるはずだ。 データと操作をデカップリングするためにVisitorパターンを使ったのだから。 「このデータに何かする操作はIOExceptionを投げうる」ということをどうやってあらかじめ知ることができるというのだろうか。 IntegerOrStringVisitorの実装クラスが増えるたびにIntegerOrStringインターフェイスまで立ち戻ってthrows節にチェック例外を追加するのはナンセンスだ。
いくつか案を検討してみよう。
案1 visitメソッドで例外処理させる
visitメソッド内で例外処理させることを要件にすれば最初のシグニチャのままでどうにかなる。でもこれは明らかに強すぎる制約で、現実的ではないと思う。
案2 visitメソッドで実行時例外に変換する
visitメソッド内でIOExceptionなどのチェック例外を適当な実行時例外に変換して投げるようにすれば、やはりシグニチャを変えずに済む。 この案の問題点は例外を捕捉する側で「より小さい例外を捕捉する」という原則に沿った例外処理ができなくなることだ。あるいは悪い言い方をすると元の例外を覆い隠す。 例えばFileNotFoundExceptionとそれ以外のIOExceptionで例外処理を変えたかったとしても、 捕捉側で受け取るのは変換後の例外なのでcatch節を分けることができない。 いや、正確に言うとgetCauseを使えば処理を変えることはできるが、どっちにしても普通の素直なtry/catchではできない。
もう一つはチェック例外を実行時例外に変換するのはJavaコンパイラが提供する安全機構を外すことであってよろしくない、 という思想なりコーディング規約なりがあるということだ。
案3 throws Exceptionと書く
最初からthrows ExceptionにしておけばVisitorがチェック例外を投げたとしてもデータやVisitorインターフェイスに後から手を入れなくても済む。 このやり方は例外変換を伴わないので案2の最初の問題も存在しない。
問題となりうるのはやはり思想・コーディング規約上のものだろう。 このようなやり方に対しては、どこからともなくチェック例外ポリスが現れてthrows Exceptionはだめだけしからんと言って笛を吹かれる可能性が高い。
また、throws Exceptionが意外に感染力が高いというのもすこしがっかりする点だ。 IntegerOrStringVisitorの実装で実際にはチェック例外を投げない処理だった場合、visitメソッドのthrows節を消すことはできるのだが、 これはあまり意味がない。 acceptメソッドが引数にとるのはあくまでもIntegerOrStringVisitorインターフェイスのvisitメソッドなので、acceptメソッドからthrows Exceptionを消すことはできない。 だから結局全体としてはExceptionを投げうるコードとみなさなければならず、acceptを呼んでいるメソッドで捕捉しないならばそのメソッドもthrows Exceptionにしなければならない。こうして誰かがcatch (Exception e)と書くまでthrows Exceptionが伝搬していく。
案4 visitメソッドで専用のチェック例外に変換する
最後の案は案2のバリエーションで、例えば次のようなチェック例外クラスを定義する。
class IntegerOrStringException extends Exception {...}
visitメソッドやacceptメソッドのシグニチャはthrows IntegerOrStringExceptionにして、visitメソッドの中でチェック例外が発生するときはこれを生成して元の例外をcauseにする。
e.accept(new IntegerOrStringVisitor {
public void visitInteger(I integer) throws IntegerOrStringException {
try {
...
} catch (IOException e) {
throw new IntegerOrStringException(e);
}
}
...
これは例外の捕捉に関して案2と同じ欠点を持つ。一方でチェック例外を実行時例外にロンダリングするわけではない。 また、案3とは異なりExceptionのサブクラスを投げるに過ぎないので例外ポリスをも満足させる。
この種の設計は一般的には「その抽象化に適した例外を投げる」(Effective Java)という考えから行われることがある。 例えばJNDIの実装がファイルを使うにしてもDBを使うにしてもlookupメソッドがIOExceptionやSQLExceptionを投げるのは実装の詳細を曝しすぎているのでNamingExceptionのサブクラスに変換して投げるべきだ、というように。 しかしVisitorの場合、この考えから案4を支持するのは無理がある。Visitorに実装される処理は「そのデータに対する何らかの処理」というだけだ。 これは何か必然性のある抽象だろうか?Visitorパターンを使わなくてすむ言語なら名前を付ける必要すらなかったものだ。
「インターフェイスを定義するときに、どういう実装になるかあらかじめわからないがthrowsをどうするか」というのはVisitorに限らずインターフェイス一般に生じる問題だ。 一般には「その抽象化に適した例外」を投げることにしているのだと思われるが、 それは結局「そのインターフェイス/パッケージ用に新しくチェック例外を定義してインターフェイスの全部のメソッドにthrowsをつけて回る」ということになっていることが多い。 かくしてJNDIのインターフェイスには全部throws NamingExceptioが、JMSのインターフェイスのすべてのメソッドにはthrows JMSExceptionがついている。 それが本当にいい設計なのかはともかくとして、これらのインターフェイスはある種の具体的な処理(名前解決、メッセージング)と結びついているので 「その抽象化に適した例外」を定義したのだと主張することはできる。しかしVisitorは処理自体を切り離したわけだから、具体性のある処理と結びついていない。 (抽象度が上がるほど「例外が表している内容」は苦し紛れになってくる。 例えばjava.util.concurrent.Future#getはExecutionExceptionというチェック例外を投げるが、これは単に任意の非同期処理の中で投げられる例外をラップしているだけだ)
そうして考えると案4は単にコーディング規約を満足させるためだけに不必要な例外クラスを定義したにすぎないと思う。
結局JavaでVisitorをやる場合はコーディング規約がどうこうといわれようとも案3をとり、throws Exceptioの伝搬を受け入れるのが妥当ではないか、と考えている。 この書き方のコードはチェック例外のないJVM言語で実行時に起こっていることと同じ動作をするものでもある。
チェック例外の特徴を整理する [Java]
Java を勉強していてエキゾチックだと感じるのはやはりチェック例外だ。このチェック例外という仕組みは、便利か邪魔か、ということはひとまず置くとしてやはり非常に興味深いものだと思う。そんな Java のチェック例外を自分なりに理解しやすいように整理・言い換えをしてみた。(これも前回と同様にかなり雑な内容だと思いますがとりあえずあきらめて記事にしてしまいます)
まずメソッドの throws 節に書かれる例外クラスを戻り値の型と比べてみよう。戻り値の型は実際に return される型と不整合があるとコンパイルエラーになる。同様に throws 節の例外クラスと実際にメソッドから投げられうる例外との間に不整合があるとコンパイルエラーになる。
いずれもメソッドのクライアントに対する契約の一部をなしているから、宣言された型より小さい型を実際に返す/投げる分には構わないが逆は不可である。例えば Object m() throws Exception {} は String を返したり IOException を投げたりできるが、String m() throws IOException は Object を返したり Exception を投げたりできない。(なお、この記事では継承関係にあってサブクラスに向かうほど小さい、逆を大きいと呼ぶ。≦と≧に対応する不等号として <: と >: を使う)
また、メソッドがサブクラスでオーバーライドされるとき、オーバーライドするメソッドの throws 節にはオーバーライドされたメソッドの throws 節と同じか、それよりも小さい型を指定しなければならない。例えば throws Exception を throws IOException でオーバーライドできるが、逆は不可である。これは Java1.5 からは戻り値についても同じである (covariant overriding)。逆に言うと例外には昔から covariant overriding があったともいえる。
戻り値とチェック例外の類似点は一応ここまでである。チェック例外は戻り値とは異なり互いに継承関係にない複数の型を指定することができる。
throws IOException, ClassNotFoundExceptionという宣言は IOException か ClassNotFoundException を投げるかもしれないが、例えば(同様に Exception の直接のサブクラスである)InterruptedException は投げないという約束になる。一方で戻り値の型は1つだけだ。
ちなみに「互いに継承関係にない」と断り書きをつけたのはもし継承関係にあればその大きいほうのクラスに包摂できるからで throws Exception, IOException というのは throws Exception というのと同じことである。
「一応ここまで」と書いたのは、次のように捉えなおすことで例外と戻り値の型とのアナロジーを引き続き維持しようという企みからである。
戻り値の型とは別に、そして例外クラス(とその階層)とも別物として、メソッドの「チェック例外に関する型」(およびその階層)を考える。これを仮に「throws の型」と呼ぶことにする。「throws の型」は単に継承関係にない例外クラスの集合として表現される型である。{IOException, ClassNotFoundException} のように表記することにする。
throws の型は次のような規則で階層をなす。
(1) 2つの throws の型が包含関係にあるとき、部分集合のほうの型のほうが小さい。したがって throws IOException, ClassNotFoundException を throws IOException でオーバーライドできる。
(2) また、throws の型の要素の一部を例外クラス階層においてより小さいものに置き換えるとより小さい型になる。したがって throws IOException, ClassNotFoundException を throws FileNotFoundException, ClassNotFoundException でオーバーライドできる。
例外クラスの階層と throws の型の階層の間の関係をいくつか例をあげて示す。
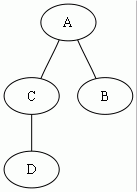
チェック例外のクラスが A, B, C の3つしかなく、以下の継承関係にあるとき、
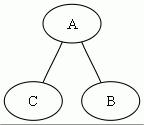
throws の型の階層は以下のようになる。
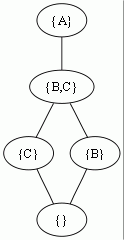
こうなる。
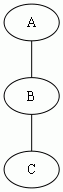
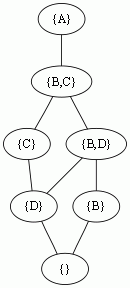
例外のクラスが A, B, C, D の4つで以下の継承関係にあるとき、
throws の型の階層は以下のようになる。(*)
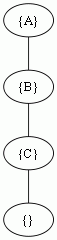
例外の階層が以下だったら、
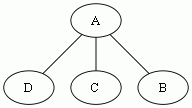
こうなる。
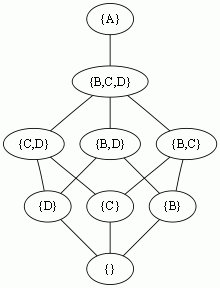
これらは全部プログラムで出力しているのできちんと変換方法を定義できるが、大雑把にいうとまず例外クラスをメンバとする全ての集合の包含関係で階層を作り、それを例外クラスの階層に基づいて正規化すると throws の型階層ができる。(TODO: throws の型階層が必ず lattice であることを示したい)
あらゆる throws の型に対して下にくる (bottom) のが空集合からなる型である。つまりどんなメソッドでも throws を書かないメソッドでオーバーライドできる(勿論 final でなければ)。あらゆる throws の型に対して上に来る型 (top) は例外クラスのルート一つだけからなる集合として構成できる(上の例ではすべて {A})。これは例外クラスがツリー階層をなす(top を持つ)ということからくる効用である。
このように throws の型を定義するとオーバーライドについて先ほどと同じ言い方を維持できる。オーバーライドするメソッドの throws 節にはオーバーライドされたメソッドの throws 節と同じか、それよりも小さい型を指定しなければならない。
話はここで終わりではない。インターフェイスが関与する場合は複数のメソッドをオーバーライドするということがありうるので、それら全ての throws の型に対して下に来るような型でなければならない。さっきの (*) を付けた図でいうと throws C と throws B, D をオーバーライドするメソッドは throws D か例外を投げないメソッドでなければならない。
throws の型の階層では2つの要素から下に辿ったときに最初に出会う地点が1つだけ決まる (meet) ので「この型と同じか、それより小さい型」という風に単一の型を使って表現できる。今の例だと「{D} か、それより小さい型」だ。
次に、throws 節に指定する型はメソッド本体の定義からも制約を受ける。メソッド本体はその実装から「こういう例外を投げうる」ということを求めることができる。Java の仕様書では "possible result" とか "can throw ..." (...は例外クラス)とかいう言葉で表現されているが、やや見通しの悪い書き方になっているので throws の型の観点から再構成してみよう。
メソッドがどんな例外を投げうるかを定式化することを考える。関数型言語などでは式の型は(日本語で書くと)以下のような規則(ML 風文法を想定)を定義して型を推論したり検査したりする。
・式 a が型αで式 b が 型βのとき、式 a; b の型はβ
・式 f が型α→βで式 a が型αのとき、式 (f a) の型はβ
・式 c が型 bool で式 t と式 f がともに型αのとき、式 if c then t else f の型はα
このやり方を throws の型に適用すると以下のようになるだろう。なお、以下でα∨βは「αとβから上に辿っていって最初に出会うところ」(join) を意味するものとする(throws の型については「和集合をとって正規化」にだいたい対応)。
・文 a が型αで文 b が型βのとき、ブロック {a; b} の型はα∨β
・式 a が型αでメソッド b が型βで式 C が型γのとき、式 a.b(c) の型はα∨β∨γ
・式 a が型αでブロック b が型βでブロック C が型γのとき、文 if (a) {b} else {c} の型はα∨β∨γ
などなど。
以上から throws の型の特徴として次のようなことが観察できる。先ほどの ML 風文法のための規則は式の組み合わせ方について型の制約を追加で課していた。これに対して throws の型は統語的な組み合わせにはまったく影響を与えない。
たったいま述べた観察に対する唯一の例外は try/catch である。(finally と catch 節複数の場合は省略)
・ブロック a が型αでブロック b が型βのとき、文 try {a} catch (E id) {b} の型は γ∨β。ただしγは{E}>:αのとき{}、それ以外のときγ∨{E}={E}∨αとなるような最小の型で、γ=αとなるときエラー
「ただし」以降は結構考えた末にこうなったけどまだ考慮漏れがあるかもしれない。「γ=αとなるときエラー」が「投げられるはずがない例外をキャッチしてはいけない」に対応している。[2008-10-28追記]もうちょっと良く考えてみると{E}>:αのとき「γ∨{E}={E}∨αとなるような最小のγ」は「γ∨{E}={E}となる最小のγ」で {} だ。だから場合わけは不要だった。こうなってみるとこの定義は Java の仕様書よりもずっといい感じだ。
こうした規則に基づいてメソッド本体の throws の型(「こういう例外を投げうる」)が求まる。メソッドの throws 節にはこうして求まった型と同じかそれより大きい型を書かなければならない。
というわけで「throws の型」という概念を導入したことによりメソッドの throws 節に書くことが許される型 T について、
「T は U 以下で L 以上のものである(ただし U はオーバーライドされる型全ての meet で、L はメソッド本体の型)」
という言い方で述べることができるようになった。
さて、throws 節に書いていい型の範囲はわかった。ところで実際にメソッドのオーバーライドをして、そのメソッド本体の throws の型がオーバーライドされるメソッドの型より小さいとき、どちらを選択する(まあ中間という選択肢はないだろうから)のが慣習として好ましいのだろう。
例えば void m() throws Exception というメソッドをオーバーライドして、メソッド本体は実際には FileNotFoundException しか投げえない場合、オーバーライドする側のメソッドには throws FileNotFoundException と書くべきだろうか、それとも throws Exception と書くべきだろうか。
サブクラスを利用するクライアントに対してより informative なのは前者のほうである。しかしこのクラスをさらに継承する側の実装者に対してより高い自由度を与えるのは後者である。こういうケースには定説があるのだろうか(例えば Effective Java みたいな本に書いてあるとか)。
Java における直列化と型 [Java]
このところめっきりプログラミングをしていないのだけど、最近は SJC-P の教科書を買って Java を勉強していて、直列化周りの言語仕様に興味と疑問が湧いた。
Java ではクラスが Serializable インターフェイスを implements すると ObjectOutputStream とかを使ってシリアライズできるようになる。この Serializable インターフェイスは実装すべきメソッドというものがない空のインターフェイスであって、これはマーカーインターフェイスと呼ばれる。
まずこのマーカーインターフェイスというのがちょっと興味深い。これは単にこの名前のインターフェイスを implements しているということだけに意味があるものだ。例えば nominal な型付けというものが全くなくて structural な型付けしか存在しないような静的なオブジェクト指向言語を考えてみると、そういう言語ではマーカーインターフェイスの居場所が無い。だからマーカーインターフェイスの用途すべてが他の仕組みに還元できるわけではないということが示せれば nominal な型付けを完全放棄してはいけない根拠の一つになるかもしれない。
次に疑問点として、何故 ObjectOutputStream#writeObject の引数は Serializable obj ではなくて Object obj なのだろうか、ということを思った。
writeObject は Serializable でないオブジェクトを受け取ると実行時エラーになる、つまりマーカーインターフェイスのマーカーは実行時に利用されているわけだけど、引数を Serializable にすると現在手に入るコンパイラの仕組みでこれをコンパイルエラーにすることができる。もっというと Serializable を implements したクラスのすべてのフィールドが直列化可能な型であるということも、やろうと思えばコンパイル時チェックできるのではないだろうか。
後半はともかく前半に対する反論を考えてみると、たまたま Object 型(や Serializable を implements していないクラス)の変数に入っているオブジェクトが実際には直列化可能だとわかっている場合(サブクラスで Serializable を implements していて、そのクラスのインスタンスである)を救えないことになってしまう。
…と思ったのだけど、そう状況ではしょうがないのでキャストすればいいのではないだろうか。一般に Serializable にキャストできないのかとも思ったけどそうでもないようだ(変換元が final でなければ可能)。その場合 NotSerializableException が ClassCastException になるだけの違いで、「キャストを使わない限りはコンパイル時に検出可能」という線までは前進できる。
それともそこまで前進しても現実的な使用では意味がないのだろうか。ひょっとしたら何か根本的な思い違いをしているような気もするけど釈然としない。
Java の本当の発明について [Java]
それはいいとして、本当に Java の発明になるものがないかといえば実はあって、「チェック例外」というものがそうだ、と思ったのだけどこれは間違ってるでしょうか。
もうひとつ、Java 以降に現れた言語で Java のチェック例外を真似した言語はない、という気もするのだけど、これは本当でしょうか。(C# には?)
ether さん

-
nice! 34
記事 322
テーマ パソコン・インターネット
プロフィール
ブログを紹介する
--



