Lua 3.0 の文法を視覚化する [Lua]
ついでに Lua 3.0 の文法も前回と同じやり方でグラフ化してみた。Lua 3.0 とわざわざ言っているのは Lua が yacc を使っていたのはこのバージョンまでで、それ以降は独自パーサになってるからだ。
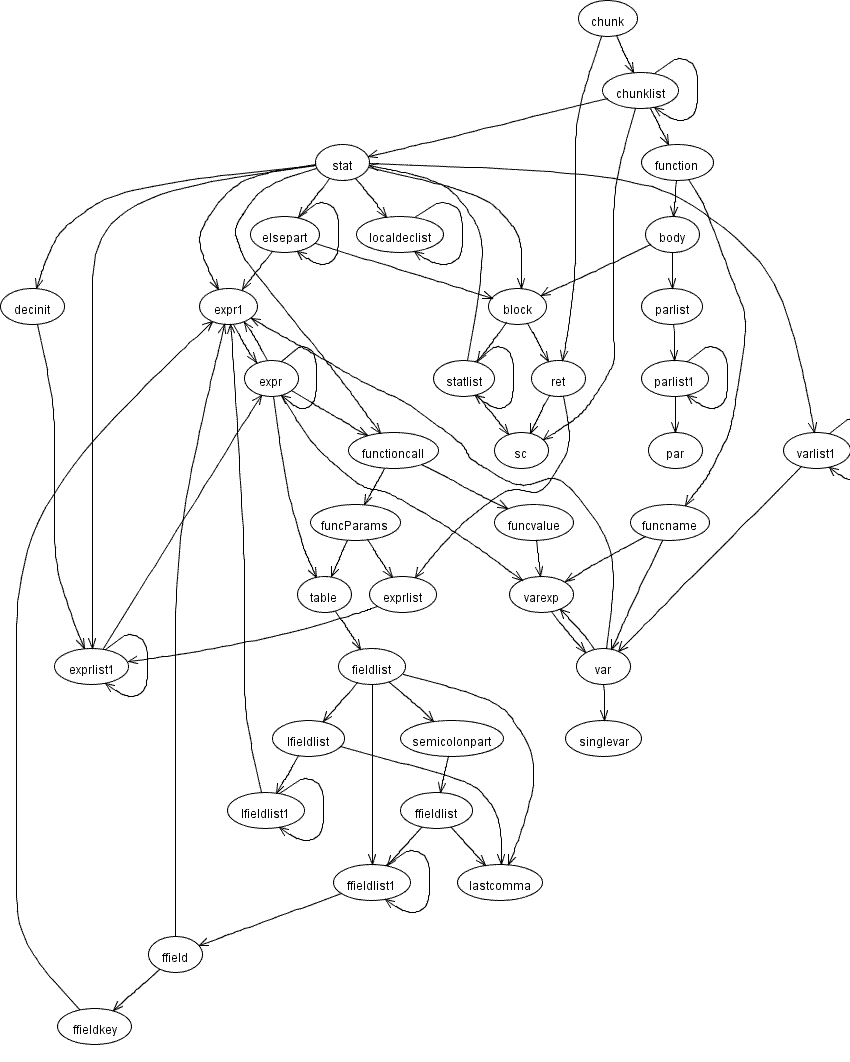
awk よりも気持ちシンプルな気がしますね。
C と Lua の間のスタック [Lua]
Tcl から Lua のコードを呼べるようなバインディングを作ろうとしていて PiL の C API の部分を読んだ。
Lua と C の間の型付けの違いとメモリ管理の違いを埋める解決策として C-Lua 間では必ず仮想スタックを使ってデータの受け渡しをするというのはへぇと思ったんだけど、実際にコードを書いてみるとなかなか見通しが悪くて苦戦する。
コードを書きながら常にスタックの状態を意識して書かなければならないわけだけど Lua の関数のどれがスタックに値を積むもので、どれが参照するだけで、どれが値を取り出して削除するものかっていうのを把握していないと変なズレが生じる。
そういうズレは当然実行時にしか検出できないのだが、ズレた次の呼び出しとかで顕在化するのでなかなか追いにくい。
基本的に何らかのまとまった処理をした後はスタックが片付いていることを前提としてよいと思うので、とりあえず以下のようなマクロを定義して、
-関数の最初には LUA_ENTER(L); と書く
-キーワードの return は直接使わず LUA_RETURN(L, X) を使う
という規約を作ることにした。
#define LUA_ENTER(L) int __stacksize = lua_gettop(L)
#define LUA_RETURN(L,X) assert(__stacksize == lua_gettop(L));return X
なお lua_gettop は仮想スタックのサイズを返す関数。
Lua の考え方 [Lua]
Programming in Lua を読んでいて気持ちがいいのは Lua の設計思想が (1) 言語仕様には最低限の仕組みだけを用意し、(2) その組み合わせで高級な概念を実現し、(3) 出来上がったものに適度な syntactic sugar をまぶし、(4) それでも生の仕組みそのものは強いて隠さない、というやりかたで一貫しているところだ。
最低限の仕組みしか用意しないといっても Tcl や Lisp のように extreme な方向に走るのではなくて、あくまで「よく整理された」という印象を受ける。きっと Lua の作者は感じのいい人に違いない。
コルーチン、イテレータ、再帰 [Lua]
頭の整理のために前回 [1] の話を比較のためのコードを書いてまとめてみた。
まず以下のようなツリー構造のデータに対して何かを行うのがプログラムの目的だとしよう。
tree =
{data = "A",
children = {
{data = "B"},
{data = "C",
children = {
{data = "D"},
{data = "E"}
},
},
{data = "F"},
{data = "G",
children = {
{data = "H"},
{data = "I"}
}
}
}
}
ツリー構造に対してもっとも自然なアルゴリズムは再帰だ。各ノードの data を表示するプログラムは以下のようなものになるだろう。
function walk(node)
print("entering walk", node and node.data or nil)
if node then print(node.data) end
if node and node.children then
for i, v in ipairs(node.children) do
walk(v)
end
end
end
walk(tree)
関数の入り口の print は動きを可視化するためにおいてある。実行すると以下のようになる。
entering walk A A entering walk B B entering walk C C entering walk D D entering walk E E entering walk F F entering walk G G entering walk H H entering walk I I
さて、ツリーの中に "F" というノードがあるかどうかを判断して表示したいという目的ができて、walk 関数を書き換えるとする。関数の2行目の print(node.data) を直接書き換えてもよいが、 Lua では関数を値として渡すことができるので以下のようにしたほうがちょっとだけ気が利いている。
function walk2(node, f)
print("entering walk2", node and node.data or nil)
if node then f(node.data) end
if node and node.children then
for i, v in ipairs(node.children) do
walk2(v, f)
end
end
end
walk2(tree, function (x) if x == "F" then print "F found." end end)
これを実行するとこうなる。
entering walk2 A entering walk2 B entering walk2 C entering walk2 D entering walk2 E entering walk2 F F found. entering walk2 G entering walk2 H entering walk2 I
これは目的を満たしているけれどもひとつ問題がある。この関数はせっかく "F" を見つけた後もツリーをすべて走査するまでは止まらず、無駄に動き続けるということだ。
再帰が適しているような問題でも常にすべての結果が欲しいというわけではないこともあるのだ。
これに対するひとつの解として、再帰アルゴリズムを採用せず、以下のように「イテレータ」を作るやりかたがある。
function add(q,v) q[#q+1]=v end
function take(q) local v=q[#q]; q[#q]=nil; return v end
function walk3(root)
local agenda = {}
add(agenda, root)
return function()
local node = take(agenda)
print("entering walk3", node and node.data or nil)
if (not node) then return false end
if node and node.children then
for i, v in ipairs(node.children) do
add(agenda, v)
end
end
return true, node.data
end
end
walk3 はイテレータのファクトリー関数だ。生成されたイテレータは "agenda" を持っていて、呼ばれるたびにそこから1要素とってノードの data を返す。ノードに子要素がある場合はその子要素を agenda に積む。次に呼ばれたときはその agenda からまた1要素取られて…という風に動作する。
なお、イテレータの戻り値が2つあるのは1つ目で「まだ残りがある」かどうかを伝えるためだ。実際のデータは2つ目の引数で返す。それから agenda の操作のために関数 add と take を定義した(やっていることはスタック操作)。
このイテレータを使うと以下のように「ツリーから "F" を探し、見つかったらやめる」という処理が書ける。
do
local iter = walk3(tree)
local live = true
local x
while live do
live, x = iter()
if live and x == "F" then
print("F found.")
break
end
end
end
実行結果は以下のとおり。
entering walk3 A
entering walk3 G
entering walk3 I
entering walk3 H
entering walk3 F
F found.
agenda に積んだのと逆順で取られるため、子要素の順序が walk, walk2 とは逆になっているが、再帰の場合と同様に深さ優先でツリーをサーチし、"F" が見つかったところで止まっている。
もうひとつの解がコルーチンを使う方法である。関数は以下のように定義される。
function walk4(node)
print("entering walk4", node and node.data or nil)
if node then coroutine.yield(node.data) end
if node and node.children then
for i, v in ipairs(node.children) do
walk4(v)
end
end
end
これはもともとの walk,walk2 関数と殆ど変わらない。違うのは「ノードの data に処理を行う」部分の代わりに coroutine.yield を使っているというところだけだ。
関数を使う側は次のようになる。ここでも "F" が見つかった時点で処理を切り上げることが可能である。
do
local iter = coroutine.create(function() walk4(tree) end)
local live = true
local x
while true do
live, x = coroutine.resume(iter)
if (live and x == "F") then
print "F found."
break
end
end
end
実行結果:
entering walk4 A entering walk4 B entering walk4 C entering walk4 D entering walk4 E entering walk4 F F found.
walk 関数をたった1箇所書き換えるだけで再帰関数が「そのまま」イテレータとして使えるようになったということが分かる(なお PiL では Lua の for 構文にアダプトするための、もうちょっと凝った書き方をしている)。
ではコルーチンがあれば walk3 形式のイテレータの作り方は覚える必要がないかというとそういうわけでもない。再帰関数は基本的にツリーに対して深さ優先の探索しかできないからだ。
一方で walk3 関数は agenda の操作の仕方を変えるだけで幅優先の探索に切り替えられる。
function add(q, v) table.insert(q,1,v) end
function take(q) local v=q[#q]; q[#q]=nil; return v end
add, take 関数を上記のように再定義してもう一度実行すると結果はこうなる。
entering walk3 A entering walk3 B entering walk3 C entering walk3 F F found.
ここでは C の子要素よりも前に C と同じ深さである F がサーチされている。
まとめ:
単純な再帰関数には以下の2点の問題がある。
1. 再帰の途中で終われない
2. 探索方法が選べない
コルーチンを使うことにより 1 は非常に簡単に解決することができる。
一方で agenda-type のイテレータを作るやり方は再帰の置き換えが必要になるが 1 を解決するとともに 2 についても柔軟に対応できる。
ところで agenda-type iterator という言葉は "Higher-Order Perl" の中で使われているのを借りているけれども、多分専門用語ではない。
[1] http://blog.so-net.ne.jp/rainyday/2006-08-24
コルーチン [Lua]
PiL の coroutine の章を読んだ。
今まで親しんできた言語でコルーチンをフィーチャーした言語は殆どなかった(Python の generator は使ったことない)ので、ちゃんと勉強するのは初めてだ。
すごいと思ったのは、例えば "Higher Order Perl" には "From Recursion to Iterators" という章があって、再帰を使ったアルゴリズムをイテレータに置き換える方法についてかなりのページを割いて説明している―それにはまあちょっとした頭の体操を要する―のだが、コルーチンを使うと「アルゴリズムは再帰のままで」結果を yield するだけでイテレータが作れる。これはあっけなくてすごい。
コルーチンの機能は一見言語自体の直接サポートがないと難しそうにも見えるけどウェブを検索してみるとコルーチンのない言語でコルーチンを実現するような工夫をしているのが無いわけでもないらしい。実現のための言語の要件が何ということがあまりよく理解できていない。要調査。
Lua と awk の共通点 [Lua]
Lua で多重代入するときに左辺の方が右辺より数が多い場合は足りない分が nil で埋められる。
> print(x,y) nil nil > x,y=5 > print(x,y) 5 nil
関数の引数の場合にもこれが当てはまるから、関数を定義されているより少ない数の引数で呼んでもエラーにはならずに―とはいっても部分適用というわけにはいかない―足りない分は nil 定義される。
> function f(x,y) print(x,y) end > f(66,77) 66 77 > f(88) 88 nil
ところでこの仮引数のスコープは関数内に限られるのでそのままローカル変数として使える。
> x,y=22,33 > function g(x,y) y=x*2; return y end > print(g(15)) 30 > print(y) 33
だから関数定義の引数列に何か変数を付け加えるとその変数が局所変数として使えるということになる。
なるほど。余計な引数を付け加えることで局所変数を定義する…ん?
awkだ!
勿論 Lua にはローカル変数を定義する local というキーワードが用意されているので awk みたいにこんなことをする必要はまったくないです。
あと前に「配列は連想配列である」っていう発想を JavaScript と比べたけど awk もそうだった。それと数値型は浮動小数点数しかないっていうのも Lua, JavaScript, awk で共通だ。
Lua の multiple results [Lua]
Lua では関数の戻り値として複数の値が返せる。
return x, y
変わっているのが、このコンマで区切られたデータの塊には特に用語として名前がついていない(PiL を読んでいて今のところ出てこない)―例えば list とか tuple とか―ということだ。
OCaml では複数の値を返す場合は tuple を使う。その戻りを tuple としてそのまま受け取ることもできるしパターンマッチを使って分解して受け取ることもできる。
# let f x = (x, x);; val f : 'a -> 'a * 'a = <fun> # let a = f 1;; val a : int * int = (1, 1) # let (b, c) = f 2;; val b : int = 2 val c : int = 2
Python でも同様に tuple を使うことができる。戻り値をひとつの変数に tuple として入れることもできるし、多重代入もできる。
>>> def f(x): ... return (x,x) ... >>> a = f(1) >>> a (1, 1) >>> b, c = f(2) >>> b 2 >>> c 2
翻って Lua では上記と同様のコードはこうなる。
> function f(x) return x, x end > a = f(1) > print(a) 1 > b, c = f(2) > print(b) 2 > print(c) 2
複数の戻り値を多重代入することはできるけどひとつの変数にまとめて代入することはできない。代入の左辺と数が合わない場合は後ろが捨てられる。
Lua では構造を持つデータ型は連想配列しかない。ここで関数は tuple に相当するような「型」の値を返しているのではない―そんな型はないのだから変数に入らない―。だからひとつずつの値しか受け取れない。
言い換えると OCaml や Python の例では戻り値は本当はひとつであり tuple 型を返すことによって「あたかも複数の値を返すかのように」見せることができるのに対して、Lua では関数の戻り値が複数だというとき、それは「本当に複数の値として」返っているのだともいえる。
さて、この「コンマで区切られたデータの塊」は代入の右辺だけではなく、関数の引数として現れてもよい。
> function g(x,y) return x+y end > print(g(13, 13)) 26 > print(g(f(13))) 26
これは OCaml で複数の引数を持つ関数を定義するのとちょっと似ている。そこでも引数は実はひとつであって tuple を使うことによってあたかも複数の引数を取るかのように見せているのだと解釈できるからだ(カリー化関数を使うこともできるけどそれは横においておく)。
# let g (x, y) = x + y;; val g : int * int -> int = <fun> # g (13, 13);; - : int = 26 # g (f(13));; - : int = 26
f(13) を括弧で括っているのはこうしないと優先順位の強さで「g を f に適用」が先に働いてしまうためだ。
Python では通常の記法の関数適用で同じ書き方をすることはできないけど apply を使った結果を見ると引数は tuple であるとみなせるようだ(この辺の理解はちょっとあやしい。Python ではもうちょっと複雑な話かもしれない)―2006-10-15追記:やっぱりこの部分の理屈はおかしい。通常の記法で適用できない以上 Python では関数の引数はタプルに還元できないと考えるほうが正当だ。
>>> def g(x, y): ... return x + y ... >>> g(13, 13) 26 >>> g(f(13)) Traceback (most recent call last): File "これらの比較から Lua の「コンマで区切られたデータのまとまり」は「変数には収まらないけどまあ大体 tuple のようなもの」と考えていいかというとそうでもないようだ。Lua では以下のようなことができる。", line 1, in ? TypeError: g() takes exactly 2 arguments (1 given) >>> apply(g, f(13)) 26
function h(x,y,z) return x+y+z end > print(h(4,13,13)) 30 > print(h(4, f(13))) 30これと同じような書き方は OCaml や Python の tuple ではできない。tuple に対してさらにコンマで値をつなげると結果は入れ子の tuple になる。
# 4, f(13);; - : int * (int * int) = (4, (13, 13))
>>> (4, f(13)) (4, (13, 13))さらに PiL には以下のような例もでてくる。これは配列を受け取ってそれらを複数の戻り値として返す。
function unpack(t, i)
i = i or 1
if t[i] then
return t[i], unpack(t, i + 1)
end
endLua の配列のサイズ [Lua]
Programming in Lua (PiL) を読み始めた。今のところの印象としては Lua は C へのインタプリタの埋め込みのしやすさという点は Tcl に似ていて、他のところは JavaScript に似ているという感じかもしれない。まあ JavaScript は殆ど使ったことが無いのだけど。
さて Lua には table 型という連想配列の型が用意されていて、普通の配列もそれを使って済ませる。つまり添字が整数なだけの連想配列だ。この発想は多分 JavaScript に似ている [1]。でも JavaScript では添字はすべて文字列扱いになるようだけど Lua では数字の添字と文字列の添字は区別される。
連想配列に # という演算子を使うとその配列の普通の配列としての大きさを調べることができる。
> a = {} -- table を作る
> a[1] = "hello"
> a[2] = "howdy"
> print(#a)
2
じゃあ整数以外の余計なエントリがあった場合はサイズはどうなるのか?と思ってやってみた。
> a["hello"] = 1 > print(#a) 2 > a[1.5] = "Guten Tag" > print(#a) 2 > a["3"] = "Buenos dias" > print(#a) 2
変わらない。なので整数とみなされる添字以外はサイズに数えられないのだ。
さらに PiL には以下のような例がある。
a = {}
a[10000] = 1
これのサイズを # 演算子で求めると 0 が返るのだ。いわく配列の終点を識別するのに nil を使う。なのでこの場合は a[1] が未定義(Lua は慣例的に配列が1オリジン!)で nil なのでそこで数えるのをやめてサイズ 0 の配列とみなす。
この記述を素朴に解釈すると配列が大きくなればなるほどサイズの算出にかかる時間は増大するように思える。本当だろうか。やってみた。
a = {}; b = {}
for i=1,2000000 do a[i]=i end
for j=1,4000000 do b[j]=j end
point1 = os.clock()
print(#a)
point2 = os.clock()
print(#b)
point3 = os.clock()
print(point2 - point1)
print(point3 - point2)
このコードを3回実験してみた結果は以下の通り。
2000000 4000000 0.96 1.51 2000000 4000000 0.93 1.46 2000000 4000000 0.86 1.34
大きいほうが時間がかかる。あまり凝ったことはしていないようだ。
[1] http://www.tokumaru.org/JavaScript/index.htm
Programming in Lua [Lua]
Programming in Lua 第2版 [1] が届いた。青紫とオレンジのツートーンカラーの表紙に Lua のアイコンが白抜きで描かれている装丁がかっこいい。内容はこれからです。
ちなみに Lua と OCaml をくっつけるというようなことは勿論やっている人がいて(Caml-listの過去ログにあったがリンク切れだった)、さらに OCaml で Lua を実装している人 [2] もいるようだ。
[1] http://www.inf.puc-rio.br/~roberto/pil2/
[2] http://www.cminusminus.org/code.html#luaml
ether さん

-
nice! 34
記事 322
テーマ パソコン・インターネット
プロフィール
ブログを紹介する
--



