論理式が矛盾しているかどうかを判定する [Lisp]
昔論理学の授業で習ったタブロー法を Scheme と SLLGEN で実装してみました。
* 速習タブロー法
タブロー法とは論理式が充足可能か矛盾しているかを確かめるアルゴリズムの一つです。
充足可能というのはその論理式が真になるような場合がありうるかということです。例えば P&Q は P が 真で Q も真であれば真になるので充足可能です。一方で P&~P は P が真であっても偽であっても真になりえないので矛盾しています。
タブロー法は
1. 与えられた論理式が全て充足可能であると仮定する
2. 論理式を展開規則によって原子式まで分解して行く。例えば「A&B=真」という仮定からは「A=真」「B=真」という2つの仮定が生じます。
3. 分解していく過程でなんらかの原子式Pについて「P=真」と「P=偽」の両方が現れたら矛盾。最後まで矛盾しなかったら充足可能。
という手順を踏んでいきます。展開規則は論理式を単純化していく方向にしか進まないので手順は必ずそのうち止まります。
また手順は分岐することもあります。例えば「A∨B=真」という仮定は「A=真」と仮定して先に進むか、「B=真」と仮定して先に進むかして、どっちかで充足可能であれば OK ということになります。
ちょっと複雑な式で例を挙げると以下の図のようになります。

演算子 &, ∨, →, ~ を使う論理式について展開規則をリストアップすると以下になります。
- A&B ⇒ AとBに分解
- A∨B ⇒ 分岐して一方にA、もう一方にB
- A→B ⇒ 分岐して一方に~A、もう一方にB
- ~(A&B) ⇒ 分岐して一方に~A、もう一方に~B
- ~(A∨B) ⇒ ~Aと~Bに分解
- ~(A→B) ⇒ Aと~Bに分解
- 原子式 P ⇒ Pは真として矛盾が無いか確かめる
- 原子式の否定 ~P ⇒ Pは偽として矛盾が無いか確かめる
* 論理式のパーサを作る
まずは論理式をプログラムで取り扱える形式にするために SLLGEN でパーサを作ります。論理式の文法というのは大体こんな感じです。
expression := <atom> | ~ <expression> | ( <expression> & <expression> ) | ( <expression> ∨ <expression> ) | ( <expression> → <expression> )
これをそのまま SLLGEN 用の文法定義に書けたらよいのですが、これは SLLGEN に受け入れられません。理由は SLLGEN が LL(1) の文法しか受け入れてくれないという大人の事情があるためで、これは1文字読んだだけでどの置き換え規則を使えばいいのか判断できないといけないということです。上記の規則は開き括弧に出会ったときの選択肢が3つ存在していて判断ができないため NG です。そこで文法を下記のように変えます。
expression := <atom> | ~ <expression> | ( <expression> <expr-rest> ) exp-rest := | & <expression> | ∨ <expression> | → <expression>
これを SLLGEN 用に書くとこうなります。
(define grammar-logic
'((expression (identifier) atom)
(expression ("~" expression) neg)
(expression ("(" expression exp-rest ")") binary)
(exp-rest ("&" expression) partial-conj)
(exp-rest ("|" expression) partial-disj)
(exp-rest ("->" expression) partial-cond)))
しかしこれによってできるデータ構造は元々ほしかったものではありません。
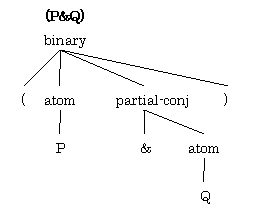
partial-conj というのが変です。これは左辺が足りなくて式になりきれていない不完全な構成素です。逆に言うと左辺が与えられれば式になれるということで、そのことを Scheme 風の言葉で表現すると (lambda (x) <<x & Q>>) ということになります。そうすると上の binary という構成素を関数適用と考えて変換すれば辻褄があうということが分かります。以上を踏まえてパーサはこうなりました。
(load "r5rs.scm")
(load "define-datatype.scm")
(load "sllgen.scm")
(define scanner-spec-logic
'((white-sp
(whitespace) skip)
(identifier
(letter) symbol)))
(define grammar-logic
'((expression (identifier) atom)
(expression ("~" expression) neg)
(expression ("(" expression exp-rest ")") binary)
(exp-rest ("&" expression) partial-conj)
(exp-rest ("|" expression) partial-disj)
(exp-rest ("->" expression) partial-cond)
(expression ("[&" expression expression "]") conj) ; dummy rule
(expression ("[|" expression expression "]") disj) ; dummy rule
(expression ("[->" expression expression "]") cond) ; dummy rule
))
(sllgen:make-define-datatypes scanner-spec-logic grammar-logic)
(define make-exp
(lambda (exp)
(cases expression exp
(atom (sym) exp)
(neg (exp) (neg (make-exp exp)))
(binary (exp rest) ((make-rest rest) (make-exp exp)))
(else exp)
)))
(define make-rest
(lambda (exp)
(cases exp-rest exp
(partial-conj (rest) (lambda (x) (conj x (make-exp rest))))
(partial-disj (rest) (lambda (x) (disj x (make-exp rest))))
(partial-cond (rest) (lambda (x) (cond x (make-exp rest))))
)))
(define parse
(lambda (input)
(make-exp
((sllgen:make-string-parser scanner-spec-logic grammar-logic) input))))
grammar-logic の最後の3つはダミールールで、これを入れておくことにより SLLGEN が自動生成してくれるデータ構造に本来欲しかった構造も付け加えることが出来ます。こうしない場合は自分で define-datatype を書けばよいです。
* タブロー法を実装する
続いて論理式が充足可能かどうか調べる satisfiable? 関数を作ります。これは先ほどのタブロー展開規則をこつこつ Scheme に直していきます。
(define satisfiable?
(lambda (exps bindings)
(if (null? exps)
bindings
(cases expression (car exps)
(atom (sym)
(let ((new-bindings (unify sym #t bindings)))
(and new-bindings (satisfiable? (cdr exps) new-bindings))))
(conj (l r)
(satisfiable? (append (cdr exps) (list l r)) bindings))
(disj (l r)
(or
(satisfiable? (append (cdr exps) (list l)) bindings)
(satisfiable? (append (cdr exps) (list r)) bindings)))
(cond (l r)
(or
(satisfiable? (append (cdr exps) (list (neg l))) bindings)
(satisfiable? (append (cdr exps) (list r)) bindings)))
(neg (exp)
(cases expression exp
(atom (sym)
(let ((new-bindings (unify sym #f bindings)))
(and new-bindings (satisfiable? (cdr exps) new-bindings))))
(conj (l r)
(or
(satisfiable? (append (cdr exps) (list (neg l))) bindings)
(satisfiable? (append (cdr exps) (list (neg r))) bindings)))
(disj (l r)
(satisfiable? (append (cdr exps) (list (neg l) (neg r))) bindings))
(cond (l r)
(satisfiable? (append (cdr exps) (list l (neg r))) bindings))
(neg (exp)
(satisfiable? (append (cdr exps) (list exp)) bindings))
(else (eopl:error 'satisfiable? ""))
))
(else (eopl:error 'satisfiable? ""))
))))
(define unify
(lambda (sym val bindings)
(let ((v (assoc sym bindings)))
(if v
(if (eqv? val (cdr v))
bindings
#f)
(cons (cons sym val) bindings)))))
satisfiable? の第1引数 exps は真と仮定される論理式のリストで最初は与えられた論理式が入りますが、展開をしていくにつれて増えたり減ったりします。展開はこのリストから1つ取って展開規則にしたがって分解したものをお尻にくっつけるという形で進行します(頭にくっつけてもいいと思う)。bindings 引数は上のタブロー図でいうと吹き出しの中に相当する部分で、これまでの展開でどの原子式が真ないし偽とされているかを保持します。
原子式の真偽が確定した時点で呼び出されるのが unify 関数で、これはもし原子式がまだ吹き出しの中に無かったら新たに原子式とその値を追加します。既にあった場合は既存の値と新しい値が矛盾するかどうかをチェックし、一致した場合はそのまま、不一致であれば #f を返します。
最後にテストをしてみます。
gosh> (satisfiable? (list (parse "(P&((Q&~P)|~P))")) '()) #f gosh> (satisfiable? (list (parse "((~P|Q)->(P->Q))")) '()) ((P . #t) (Q . #f)) gosh> (satisfiable? (list (parse "((P&Q)->~~P)")) '()) ((P . #f)) gosh> (satisfiable? (list (parse "(P&~P)")) '()) #f
以上タブロー法でした。
EOPL と異なる再帰関数実装 [Lisp]
EOPL の再帰関数の実装について sumii さんがさらなる alternative な実装について書かれています。
[1] http://d.hatena.ne.jp/sumii/20071105/p1
[2] http://d.hatena.ne.jp/sumii/20071107/p1
大変ためになったので理解するためにコードを写経してみました(後掲)。
写経しているうちに [2] のほうの記事の「整数とクロージャの組」は整数をクロージャのレコードに含めてしまうほうが簡潔なのではという気がしてきたのでそう変えてみました。
こうすると (if (and (pair? proc) (number? (car proc)) (procval? (cdr proc))) ...) みたいな箇所は (if (procval? proc) ...) でよくなるほか、あまり car とか cdr を書かなくて済みます。
一応 letrec even(x) = if x then (odd sub1(x)) else 1 odd(x) = if x then (even sub1(x)) else 0 in (odd 13) や letrec f(x) = x in eq?(f,f) のようなテストで期待値が出ますが、いやそれでは意味が変わる場合がある、効率が落ちる、などがあったら指摘いただけると幸いです。
長いけど全コード掲載。
EOPL 第3章の Exercise 3.34 から 3.36 [Lisp]
3.6 節では letrec を追加して再帰関数を定義できるようにする。この EOPL 言語には大域変数はないので関数内関数の再帰に相当する話になる。
興味深かったのは、私は再帰をする場合は循環構造が出来るので完全な関数型的には書けずに破壊的更新をどこかでしなければならなくなるんだろうと思っていたのだけど、クロージャの生成を apply 時まで遅延させるやり方ではコード上のどこにも非関数的な記述がでてこなくてよい。ただこれだと関数が必要になるたびにクロージャの生成が行われるので循環構造を作ったほうが効率がよい。
練習問題 3.34 は「名前なし環境」でこの再帰を出来るように拡張するという問題で、3.35 はクロージャの生成が「最大1回」(不要なときは生成されない)になるようにする。この2つをまとめてやった。
ここでは例えば
letrec fact(x) = if x then *(x,(fact sub1(x))) else 1 in (fact 5)
という プログラムから以下の構文木ができることになる。
(a-program
(letrec-exp (fact)
((x))
((if-exp (lexvar-exp 0 0)
(primapp-exp (mult-prim)
((lexvar-exp 0 0)
(app-exp (lexvar-exp 1 0)
((primapp-exp (decr-prim)
((lexvar-exp 0 0)))))))
(lit-exp 1)))
(app-exp (lexvar-exp 0 0) ((lit-exp 5)))))
「最大1回」はメモ化の要領で実現した。
[追記] よく見たらメモ化の条件分岐がすっぽり抜けてたのを修正。ついでに 3.36 の回答もマージした。毎回クロージャを作る実装と1回しか作らないのとでは eq? が関与するプログラムで違いが出る。
XLISP-STAT を Windows でコンパイルする方法 [Lisp]
XLISP-STAT を Windows でコンパイルする場合の注意点。単なる備忘です。
コンパイラには Borland C++ 5.5 を使います。ソースは [1] の xlispstat-3-52-20.tar.gz をダウンロードして入手します。最初からバイナリがほしければその下の mswin ディレクトリにコンパイル済みバイナリ(WXLS32ZP.EXE が32ビット版)があります。
このソースを適当な場所に解凍して中の msdos ディレクトリまで降りて makefile の BCDIR を bcc のルートディレクトリに書き換えて make を実行するというのが基本的な手順ですが、2箇所はまりどころがありました。
1. リソースファイルのデコード
アイコンやカーソルなどのリソースファイルはそのままの形ではなく .uu という拡張子で icons ディレクトリや cursors ディレクトリに存在しています。これは uuencode 形式なのでデコードしてやる必要がありますが、ただ make してもやってくれません。Windows には uudecode は付いていないので以下のような Tcl スクリプトを書いてデコードしました。
package require uuencode
set uu [::uuencode::uudecode -file [lindex $argv 0]]
set fn [lindex [lindex $uu 0] 0]
set bin [lindex [lindex $uu 0] 2]
set f [open $fn w]
fconfigure $f -encoding binary
puts -nonewline $f $bin
close $f
2. コンパイルオプションの一部変更
そのままの makefile でビルドすると最後の最後で以下のように言われてしまいます。
Error: 外部シンボル '_errno' が未解決(D:\XLISPSTAT-3-52-20\MSDOS\XLFIO.OBJ が参照)
これは makefile 内の CFLAGS の -W を -WM に変えると通るようになります。
[1] ftp://ftp.stat.umn.edu/pub/xlispstat/current/
EOPL 第3章の Exercise 3.31 から 3.33 [Lisp]
3.31 は動的スコープを実装するもう一つの方法として、グローバルなスタックにバインディングを置いてプロシージャの始まる時に push、戻る時に pop するというもの。
3.32 は動的スコープだと再帰は特別なことしなくてもできるよという話で、3.33 はレキシカルスコープと違って動的スコープだと変数の名前をうっかり変えただけで思いもよらぬところに影響が出て分かりにくいよという話。
さてこれで 3.5 節の練習問題がやっと片付いた。3.19 からちまちまと1ヶ月くらいやってたけどこれでたったの4ページ分しか進んでいない。
EOPL 第3章の Exercise 3.27 と 3.28 [Lisp]
今まではクロージャ=関数本体+環境を作るときの環境として「クロージャが作られた時点での環境全体」を使ってきた。練習問題 3.27 と 3.28 ではこれを「クロージャが作られた時点の環境のうち関数本体で自由変数であるもの」(つまり必要なバインディングのみから成る環境)に変える。
この結果、例えば
let x = 1 in let y = 2 z = 3 in let f = proc (i) +(x,+(z,i)) in (f 3)
の f にくっつく環境は
(((y z) . #(2 3)) ((x) . #(1)) ((i v x) . #(1 5 10)))
ではなくて(最後の (i v x) は環境の初期値)
(((x z) . #(1 3)))
のようなフラットなものになる。
これに練習問題 3.24 のような lexical-address 関数を付けると
(lexvar-exp f 0 0) found at [0 : 0]
(lexvar-exp x 2 0) found at [1 : 0]
(lexvar-exp z 1 1) found at [1 : 1]
(lexvar-exp i 0 0) found at [0 : 0]
となり、x と z の位置が予測と一致しなくなるので合うように作り変えるのが練習問題 3.28 だ(本当はさらに名前でなく lexical address を使って評価を行うように作り変えるという注文もあるんだけどめんどいので省略)。
ところでこのような改変は一体どんな利点があるんだろうか。一見節約している風だけど、逆に環境を作り直す分だけメモリやコストがかかるような気もする。ルックアップが速くなるかといえば微妙な感じだ。環境がいままでやってきたような関数的な実装じゃなかったとしたらバインディングを限定することの利点はありそうだけど。
それと現実の言語実装ではどうするのが多いのか?思い出したのはたしか Python のクロージャの中で locals 関数を使ってローカル変数の一覧を出すと「ローカル変数+環境のうちクロージャ内で使われている変数だけ」を出してくれるはずだけど Python ではひょっとしてこういう分析をしているのかな。
EOPL 第3章の Exercise 3.25 [Lisp]
前回のレキシカル変数に名前は不要というアプローチを推し進めて環境から完全に名前を消してしまう。これにより env 系の関数は非常に単純になった。プログラムの字面の解析を事前に手厚くしておく分だけ実際の実行が単純になるということかな。
前回の練習問題では lexical-address 関数が変数を lexvar に変換できなかった場合(つまり自由変数の場合)も考慮しておいたのだけど env 系関数から変数名が消えたことによりこれが意味をなさなくなった。あわせて init-env から組み込みのバインディグを削除した。
ここでは束縛されない変数が現れた場合は実行時(eval 時)のエラーにしたけどプログラム解析の段階でエラーにすることもできると思う(lexical-address 内の get-address 関数の4行目)。
ether さん

-
nice! 34
記事 322
テーマ パソコン・インターネット
プロフィール
ブログを紹介する
--



