初めて再帰モジュールが必要になった話 [OCaml]
入力ストリームの実装から独立したパーサーを定義したい。 そこでまずは入力ストリームのデータ型を定義する。
module type INSTREAM = sig
type instream
(* 本当はinstreamに対する色々な操作を含むつもり *)
end
実際の入力元はチャネルだったりメモリ上の文字列だったりする。
module ChanIns = struct
type instream = in_channel
end
module StringIns = struct
type instream = string
end
パーサーのシグニチャと実装はこんな感じになる。
module type PARSE = sig
type instream
type result
val parse : instream -> result
end
module Parse(I: INSTREAM): PARSE with type instream = I.instream
= struct
type instream = I.instream
type result = unit
let parse ins = ()
end
module StringParse = Parse(StringIns)
module ChanParse = Parse(ChanIns)
ここでparse関数の中で、 「ストリームから読み込んだデータをいったん文字列にしてparse関数自身でパースする」 という処理がしたい。 文字列が変数sだとして、その内部のparse関数の呼び出しはどのように書けばよいか。
単にlet rec parse ins = ...としてparse (s : string)では駄目そうだ。
parseの型はinstream -> resultなのだがinstreamはI.instreamであって、
stringであるとは限らない。
じゃあ StringParse.parse (s : string) では?というとこれもだめだ。
Parseの実装の中ではまだStringParseは定義されていない。
もちろんStringParseはParseに依存するのでParseより前に移動するわけにもいかない。
ということは…あ、再帰か。 ということで初めて実際に再帰モジュールというものが必要になる場面に出くわしたのだった。
結論から書くと、次のように書くことでコンパイルが通るようになる。
module Parse(I: INSTREAM)(S: PARSE with type instream = StringIns.instream)
: PARSE with type instream = I.instream
= struct
type instream = I.instream
type result = unit
let parse ins = (ignore (S.parse ""); ())
end
module rec StringParse : PARSE with type instream = StringIns.instream =
Parse(StringIns)(StringParse)
module ChanParse = Parse(ChanIns)(StringParse)
ファンクターは新しい引数Sをとる。 Sのモジュール型から、S.instreamはStringIns.instreamであるという想定がおけるので、 問題のparseの呼び出しはこのSに定義されたparseを呼ぶことでよくなる。
S.parseは結果的にはStringParse.parseを呼んでいることにしたい、 つまりS = StringParseであるということにしたいので、 ファンクターを適用するときに第2引数をStringParseにする必要がある。
これはChanParseのときは簡単な話で、普通に適用すればよい。 しかしStringParseを作るときは自分自身を使って自分自身を作るということになる。 これは再帰だ。ということでrecが付く。 再帰モジュール定義の場合はStringParseのモジュール型を明示する必要があるようだ。
後書き
実際にはSMLを書いていてこの問題に遭遇したのでこのように解決することはできませんでしたが、 そういえばOCamlには再帰モジュールって有ったと思い出して問題を翻訳しました。
ユーザー定義のdistfix/mixfix演算子をパースする [OCaml]
プログラミング言語で演算子というと普通は中置演算子(infix)だが、C言語の++のように前置演算子(prefix)や後置演算子(suffix/postfix)もある。
?:のような演算子はどうかというと3項演算子(tertiary operator)と呼ばれる。 この言葉は3という数字に限定されているし、syntacticな特徴―複数要素から成り、間に被演算項が入る―を表現していない。(f(x,y,z)の形でも3項ではある)
もっと一般的にはどういうのかというと、プログラミング言語の世界ではdistfixまたはmixfixというようだ。[^1]
中置演算子もそうだが、distfixを任意の識別子に対して任意の優先度でユーザー定義できるようにしようとすると、パーサーの動作を動的に変更する必要が出てきて結構大変になる。 一方で、それらの演算子をlexicalに区別できるようにして優先度も固定するならば通常のパーサージェネレーターを使って割と簡単に実現できる。
そういう方法がHaskell界で有名なSimon Peyton JonesさんのParsing distfix operators という古いペーパー(以下PJ(1986)と書く)に書いてあったのでそれを参考にOCamlで実装してみた。
字句解析
まずユーザー定義できる前置、中置、後置演算子を字句解析で区別する方法について、PJ(1986)ではそれぞれ後ろ、両端、前にドットをつけるという方式を採用している。
例えばx .plus. yと出てきたら.plus.はユーザー定義の中置演算子と解釈される。また、これはplus x yと同じものとして解析されるので演算子を定義するときは単に plus という関数を定義すればよい。
こうするとplusという関数をそのままplus x yとして使うこともできるしx .plus. yとして中置演算子として使うこともできる。
ここではドットではなくバッククォートを使うことにした。
LexPeyton.mll
{
(中略)
let drop s = let len = String.length s - 1 in String.sub s 1 len
let chop s = let len = String.length s - 1 in String.sub s 0 len
let untick s = let len = String.length s - 2 in String.sub s 1 len
}
(中略)
let l = ['a'-'z' 'A'-'Z' '\192' - '\255'] # ['\215' '\247'] (* isolatin1 letter *)
let d = ['0'-'9'] (* digit *)
let i = l | d | ['_' '\''] (* identifier character *)
rule token =
parse
(中略)
| '`' i+ { let id = lexeme lexbuf in Postfix (drop id) }
| '`' i+ '`' { let id = lexeme lexbuf in Infix (untick id) }
| l i* '`' { let id = lexeme lexbuf in Prefix (chop id) }
| '`' { Postfix "" }
| l i* ('`' i+)* '`'? {let id = lexeme lexbuf in Ident id}
disfixを使わないならば関数名の識別子に特別な考慮は要らないが、distfixは前置、中置、後置演算子の組み合わせで実現されるので、そのような組み合わせを表現できるようになっていなければならない。これはユーザー定義演算子を区別するのにつかった記号(バッククォート)とは別でも構わないと思うが、ここでは同じバッククォートを用いた。
例えばif` x `then` y `else` z `fiのように使われる演算子を関数定義するときはif`then`else`fiという名前を使う。そのため識別子Identにバッククォートを含められるようにした。
構文解析
ocamlyaccファイルは次の通り。
ParPeyton.mly
%{
(中略)
let rec slide exp word = match exp with
VarExp(f) -> VarExp(f ^ "`" ^ word)
| AppExp(e, a) -> AppExp(slide e word, a)
| e -> failwith (AbsPeyton.show e ^ " + " ^ word)
(中略)
%}
(中略)
%%
exp : exp0 Eof { $1 }
exp0 : Let Ident Eq exp0 In exp0 { LetExp($2, $4, $6) }
| If exp0 Then exp0 Else exp0 { IfExp($2, $4, $6) }
| Fun Ident Eq exp0 { FunExp($2, $4) }
| exp1 { $1 }
exp1 : exp1 Postfix { AppExp(VarExp($2), $1) }
| exp2 { $1 }
exp2 : exp2 Infix exp3 { AppExp(AppExp(VarExp($2), $1), $3) }
| exp3 { $1 }
exp3 : exp3 Add exp4 { AppExp(AppExp(PrimAdd, $1), $3) }
| exp3 Sub exp4 { AppExp(AppExp(PrimSub, $1), $3) }
| exp4 { $1 }
exp4 : exp4 Mul exp5 { AppExp(AppExp(PrimMul, $1), $3) }
| exp4 Div exp5 { AppExp(AppExp(PrimDiv, $1), $3) }
| exp5 { $1 }
exp5 : exp5 exp6 { AppExp($1, $2) }
| exp6 { $1 }
exp6 : Integer { IntExp($1) }
| Ident { VarExp($1) }
| distexp Postfix { slide $1 $2 }
| LParen exp0 RParen { $2 }
distexp : Prefix exp3 { AppExp(VarExp($1), $2) }
| distexp Infix exp3 { AppExp(slide $1 $2, $3) }
;
後置演算子と中置演算子はそれぞれexp1とexp2に定義されている。これは特筆することはない定義で、semantic actionで関数適用の構文を作るために順序を入れ替えたりするようにしている。
distfixは一番結合度の高いexp6の定義から始まる。これはつまり「distfixとは前置演算子と式で始まり、0組以上の中置演算子と式の後に後置演算子で終わる」という定義である。 解析木としては前置演算子が一番内側、後置演算子が一番外側に来るような形になる。
これを通常の関数適用の構文木にアダプトするために使っているのがslideという関数だ。この関数は後からくっつく方の演算子(中置、後置演算子)を予め適用されている演算子にくっつける働きをする。(なおPJ(1986)の同名関数はSaslという言語で書かれていたのだけど、どうにも型がつけられそうにないような定義になっていてよくわからなかったので適当に改変した)
ソースの全体はGistにアップロードした。
所感
演算子の優先順位には結構微妙なところがある。
たとえばdistexpに含められる式はexp3としているが、これをexp2やexp1にするとshift-reduce conflictが起こる。
もしexp1がdistfixの中に現れることができるとするとたとえばa` 0 `b` 1 `cという文をa`b`c 0 1と解釈するかa`c (b 0 1) = a` (0 `b` 1) `cと解釈するかで多義的になってしまう。
exp2の後置演算式についても同様で、exp2がdistexpに現れてよいとabout` 2 `years `agoは(about` 2 `years) `agoかabout` (2 `years) `agoかの多義になる。
これはまあしょうがないのだが単純な後置演算式の結合度がかなり弱いというのはなんとなく直観に反するかもしれない。
あとこの文法定義ではdisexpは必ず後置演算子で終わらなければならない。exp6にdistexp単独のルールを追加するとshift-reduce conflictが起こる。
これはmultiply` x `by` y + zのような式が(multiply` x `by` y) + zなのかmultiply` x `by` (y + z)なのか(multiply` x) `by` (y + z)なのか((multiply` x) `by` y) + zなのか多義になってしまうためである。
distexpの中に現れてよい式のレベルをもっと下にすると大体の衝突は回避できるけどその代り結局括弧が必要になるし、中置演算子をshiftするかどうかのconflictはそれでも解消されない。
英語の構文を模倣すると後置演算子で終わることになることはまずない(英語には基本的に後置詞というものがないので)のでこれはとても惜しい点だ。
`fiとか`endとか`doneみたいなのを多用するのはあまり簡潔とは言えない。でも括弧をやたらと書くよりはましだろうか。ただし上記の字句解析では単に`を書いた時にも後置演算子になるようにしたのでmultiply` x `by` y `とは書ける。(multiply`by`という関数が対応する)
なお、PJ(1986)ではpartial insantiationというのも提案されていた。これはたとえばif`then`else`fiを定義して、if` `then` 0 `else` 1 `fiという風に一部を埋めない形で使うと関数の部分適用のようになるというものだった。これはなんというか、できても使わないだろうと思ったので上記の文法定義には含めていない。
[^1]: prefix/suffix/infixが明らかに言語学から来ている用語なのに対してdistfix/mixfixはおそらくプログラミング言語の世界で造語されたと思われる。 なおprefix/infix/suffixは言語学ではlexicalなレベルで起こる事象に使うのに対してプログラミング言語の世界では演算子のsyntacticな配置に対して用いられるのでちょっと用法が違う。
OCamlで128行で作るJVMバイトコードコンパイラ [OCaml]
一昨年に出版されたImplementing Programing Languages <http://www.digitalgrammars.com/ipl-book/> という本(以下IPL)を読んでいました。
この本は名前の通りインタプリタ/コンパイラの実装についての本ですが、とてもいい本です。何がまずいいかというと、薄い(そして安い)。207ページしかありません。コンパイラ作りたいとなったらドラゴンだのタイガーだのと格闘しなければならないという先入観がありますのでこの薄さは画期的です。
内容の深さという意味では他の本に譲る点はあるのでしょうが、一通りのことが実践できるようになるまでを要領よく解説していて、かつ最初は読み飛ばしてもいい理論部分にもわざわざ印をつけてくれているので、おそらくコンパイラ作成志望者にとっての最短コースを示してくれる本だと思います。
飛ばし読みの成果としてJVMバイトコードを生成する簡単な言語処理系を作ってみることにしました。
文法の定義
文法の定義はIPLでも使っているBNFCという文法定義言語/ツールを使います。ツールはUbuntuではapt-getで入れられます。
言語名は仮にTauとしました。データは整数のみで、条件分岐と四則演算とローカル変数定義と関数呼び出しを持ち、しかしループは持ちません。関数定義はトップレベルに1つのみ、引数も1つのみに限定しました。
Tau.cfというファイル名で文法を定義します。
Func. Func ::= "fun" Ident "(" Pat ")" "=" Exp ;
Add. Exp ::= Exp "+" Exp1 ;
Sub. Exp ::= Exp "-" Exp1 ;
Mul. Exp1 ::= Exp1 "*" Exp2 ;
Div. Exp1 ::= Exp1 "/" Exp2 ;
Atm. Exp2 ::= Atom ;
coercions Exp 2 ;
Let. Atom ::= "let" Pat "=" Exp "in" Exp ;
Cnd. Atom ::= "if" Exp "then" Exp "else" Exp ;
Int. Atom ::= Integer ;
Var. Atom ::= Ident ;
Exp. Atom ::= "(" Exp ")" ;
App. Atom ::= Ident Exp ;
VarPat. Pat ::= Ident ;
これをBNFCにかけると、この文法から大体想像がつくような抽象構文木データ型とパーサージェネレータ用のソースが生成されます。簡単!
この文法だとFunc, Exp, Atom, Patという直和データ型ができて、Add, Sub...などのコンストラクタができるわけです。(※追記: この文法定義は関数適用の優先順位が一般的に期待されているのと異なる点やshift-reduce conflictが起こる点でちょっといまいちだとあとで分かったのですが、とりあえずそのままにしておきます。またcoercionを定義していれば Exp. Atom ::= "(" Exp ")" ; のルールは不要でした。)
パーサージェネレータは昔はコンパイラコンパイラと呼ばれていましたので、BNFCはコンパイラコンパイラコンパイラということになるのだそうです。
IPLではHaskelとJavaが説明に使われていますが、BNFCツール自体はOCaml(ocamlyacc/ocamllex)やその他の言語にも対応していますのでここではOCamlを使います。
bnfc -ocaml -m Tau.cf
-mはMakefileを生成するオプションです。
構文木からJavaアセンブラへの変換
構文木に対する操作を行うコードは自分で書く必要がありますが、一緒にSkel[文法名].ml(ここではSkelTau.ml)というスケルトンのソースも生成されるのでそれを元に作ればよいです。
IPLを参考にしつつ、構文木をJVMバイトコードに変換するためのソースを書きました。
module Compile = struct
open AbsTau
type label = string
type instr =
Label of label | Ldc of int | Iadd | Isub | Imul | Idiv | Ifeq of label
| Goto of label | Ireturn | Return | Aload of int | Invokenonvirtual of string
| Iload of int | Istore of int | Invokestatic of string
type env = int ref * (string, int) Hashtbl.t
let extend_env name (top, tbl) = (Hashtbl.add tbl name (!top); incr top)
let lookup_env name (_, tbl) = Hashtbl.find tbl name
let empty_env () = (ref 0, Hashtbl.create 10)
let label_index = ref 0
let new_label () = (label_index := (!label_index + 1); "LABEL" ^ string_of_int (!label_index))
let emit = function
Label l -> print_endline @@ l ^ ":"
| Ldc i -> print_endline @@ "\tldc " ^ string_of_int i
| Iadd -> print_endline "\tiadd"
| Isub -> print_endline "\tisub"
| Imul -> print_endline "\timul"
| Idiv -> print_endline "\tidiv"
| Ifeq l -> print_endline @@ "\tifeq " ^ l
| Goto l -> print_endline @@ "\tgoto " ^ l
| Ireturn -> print_endline "\tireturn";
| Return -> print_endline "\treturn";
| Aload i when i <= 3 -> print_endline @@ "\taload_" ^ string_of_int i
| Aload i -> print_endline @@ "\taload " ^ string_of_int i
| Invokenonvirtual m -> print_endline @@ "\tinvokenonvirtual " ^ m
| Iload i when i <= 3 -> print_endline @@ "\tiload_" ^ string_of_int i
| Iload i -> print_endline @@ "\tiload " ^ string_of_int i
| Istore i when i <= 3 -> print_endline @@ "\tistore_" ^ string_of_int i
| Istore i -> print_endline @@ "\tistore " ^ string_of_int i
| Invokestatic m -> print_endline @@ "\tinvokestatic Tau/" ^ m ^ "(I)I"
let rec compileFunc (x : func) env = match x with
Func (Ident name, VarPat (Ident param), exp) -> (
extend_env param env;
print_endline @@ ".method public static " ^ name ^ "(I)I";
print_endline ".limit locals 256";
print_endline ".limit stack 256";
compileExp exp env;
emit Ireturn;
print_endline ".end method")
and compileExp (x : exp) env = match x with
Add (exp0, exp) -> (compileExp exp0 env; compileExp exp env; emit Iadd)
| Sub (exp0, exp) -> (compileExp exp0 env; compileExp exp env; emit Isub)
| Mul (exp0, exp) -> (compileExp exp0 env; compileExp exp env; emit Imul)
| Div (exp0, exp) -> (compileExp exp0 env; compileExp exp env; emit Idiv)
| Atm atom -> compileAtom atom env
and compileAtom (x : atom) env = match x with
Let (VarPat (Ident name), exp0, exp) -> (
extend_env name env;
compileExp exp0 env;
emit @@ Istore (lookup_env name env);
compileExp exp env)
| Cnd (exp0, exp1, exp) ->
let false_label = new_label () in
let true_label = new_label () in (
compileExp exp0 env;
emit (Ifeq false_label);
compileExp exp1 env;
emit (Goto true_label);
emit (Label false_label);
compileExp exp env;
emit (Label true_label))
| Int n -> emit (Ldc n)
| Var (Ident name) -> emit @@ Iload (lookup_env name env)
| Exp exp -> compileExp exp env
| App (Ident name, exp) -> (
compileExp exp env;
emit @@ Invokestatic name)
let compile func = (
print_endline @@ ".class public Tau";
print_endline ".super java/lang/Object";
print_newline ();
print_endline ".method public ()V";
emit (Aload 0);
emit (Invokenonvirtual "java/lang/Object/()V");
emit Return;
print_endline ".end method";
print_newline ();
compileFunc func (empty_env ()))
end
open Lexing
let parse (c : in_channel) : AbsTau.func =
ParTau.pFunc LexTau.token (Lexing.from_channel c)
let main () =
let filename = Sys.argv.(1) in
let channel = open_in filename in
try
Compile.compile (parse channel)
with BNFC_Util.Parse_error (start_pos, end_pos) ->
Printf.printf "Parse error at %d.%d-%d.%d\n"
start_pos.pos_lnum (start_pos.pos_cnum - start_pos.pos_bol)
end_pos.pos_lnum (end_pos.pos_cnum - end_pos.pos_bol);
;;
main ()
ちょっとスタイルが命令的すぎる感じもしますが、IPLでもコード生成のところは凝ったことしないで命令的に書いたほうがいいよと言っているんですね。
JVMバイトコード出力と書きましたが、実際にはJasminというアセンブラ用のアセンブリを出力しています。 関数はJVM世界の静的メソッドに対応します。JVMのメソッドは何らかのクラスに属する必要がありますのでTauというクラスに属させることにしました。
このソースをMakefileをいじってビルドします。
サンプルプログラム
おなじみの階乗計算はこの言語ではこのように書きます。
fun f(x) =
if x then
x * f (x - 1)
else 1
これを先ほど作成したコンパイラにかけるとJasminソースができます。
$ ./tau fact.tau .class public Tau .super java/lang/Object .method public()V aload_0 invokenonvirtual java/lang/Object/ ()V return .end method .method public static f(I)I .limit locals 256 .limit stack 256 iload_0 ifeq LABEL1 iload_0 iload_0 ldc 1 isub invokestatic Tau/f(I)I imul goto LABEL2 LABEL1: ldc 1 LABEL2: ireturn .end method
一度ファイルに落としてからjasmin(これもapt-getで入れられます)でアセンブルするとクラスファイルが出来上がります。
$ ./tau fact.tau > Tau.j
$ jasmin Tau.j
$ javap -cp . Tau
Compiled from "Tau.j"
public class Tau {
public Tau();
public static int f(int);
}
ドライバ
このクラスはpublis static int f(int)という静的メソッドを含むだけのクラスなので計算結果を表示するためにはドライバが必要です。これは面倒なのでJavaで書きましょう。
public class Driver {
public static void main(String[] args) {
System.out.println(Tau.f(Integer.parseInt(args[0])));
}
}
これをコンパイル、実行すると階乗関数を呼び出してくれます。
$ javac -cp . Driver.java $ java -cp . Driver 10 3628800
一応電卓で検算すると…あってました。
ローカル変数も使ってみます。
$ cat a.tau fun f(x) = let a = x + 3 * 4 in 5 + 6 * a $ ./tau a.tau > Tau.j $ jasmin Tau.j $ java -cp . Driver 2 89
できてますね。
BNFC生成コードを除外して、自分で書いた部分文法定義とコード生成箇所だけを合計すると126行しか書いていませんでした。なかなかいい感じだと思います。
$ cat Tau.cf Compile.ml | wc -l 126
ウクレレのコードを見つけるプログラム [OCaml]
ウクレレやギターのようなコードを弾く弦楽器では同じコードを弾くのにも何通りもの押さえ方が存在します。
ウクレレで C のコード(C, E, G の3音)を鳴らす場合を例にとりましょう。ウクレレには4本の弦があり、何も押さえない状態では1弦から4弦まで順に A, E, C, G の4つの音を出します。A の音はCコードの構成音ではないので1弦の3フレットを押さえます。これにより1弦から出る音は A から3つ (A->Bb->B->C) シャープした C の音になって C, E, C, G の音が出るわけです。
一方で1弦7フレットを押さえても C のコードと見なせます。A から7つ分シャープすると A->Bb->B->C->C#->D->Eb->E となり、鳴る音は E, E, C, G となります。これも C, E, G で構成されるのでCのコードと言えるのです。
このような何通りもの押さえかたは一番高い音を何にしたいかといった理由などで使い分けますが、市販の教則本等のコード一覧に押さえ方としても載っているのはそのうちの代表的な1つか、コードブック的なもので各々3つくらいです。タブ譜などを見ながら押さえ方の難しいコードが出てきて「もうちょっと楽な押さえ方はないのか?」というときに自分で編み出すのはなかなか大変ですので自動で計算するプログラムを OCaml で書いてみました。
まずは型定義です。音名をヴァリアント型で定義します。
type tone = C | Db | D | Eb | E | F | Gb | G | Ab | A | Bb | B
これは整数で表現したほうが演算(シャープするとかフラットするとか)ができていいという考え方もあるかもしれませんが、今回のプログラムでは特に不要だったのでヴァリアント型にしました。異名同音(C#とDbとか)はすべてフラットのほうの書き方にしていますが、これはヴァリアント型のコンストラクタに記号が使えないためです。
次にいくつかタイプエイリアスを定義します。
type chord = tone list type position = tone * int type string_ = position list type form = position list type state = form * string_ list
実を言うと実際に後で型注釈とかをして使うわけではないのですが、一応気分の問題で定義しておきました。コード chord は音名を集めたものです。ポジション position は何フレット目を押さえると何の音が出るかを示しています。弦 string_ はポジションを1列に並べたものです。フォーム form は各弦のどのポジションを押さえてコードを鳴らすかを表現します(要素数4つのリストです)。state がよくわからないと思いますが、これは後で説明します。以下、型を説明するときはこれらを使います。
次にウクレレの4つの弦を表現するデータを定義します。
let rec iota m n = if m = n then [n] else m :: iota (m + 1) n let a_string = List.combine [A; Bb; B; C; Db; D; Eb; E; F; Gb; G; Ab] (iota 0 11) let e_string = List.combine [E; F; Gb; G; Ab; A; Bb; B; C; Db; D; Eb] (iota 0 11) let c_string = List.combine [C; Db; D; Eb; E; F; Gb; G; Ab; A; Bb; B] (iota 0 11) let g_string = List.combine [G; Ab; A; Bb; B; C; Db; D; Eb; E; F; Gb] (iota 0 11) let strings = [a_string; e_string; c_string; g_string]
これは以下のような構造を作っています。(note * int) list list は気分としては string_ list です。
# strings;; - : (note * int) list list = [[(A, 0); (Bb, 1); (B, 2); (C, 3); (Db, 4); (D, 5); (Eb, 6); (E, 7); (F, 8); (Gb, 9); (G, 10); (Ab, 11)]; [(E, 0); (F, 1); (Gb, 2); (G, 3); (Ab, 4); (A, 5); (Bb, 6); (B, 7); (C, 8); (Db, 9); (D, 10); (Eb, 11)]; [(C, 0); (Db, 1); (D, 2); (Eb, 3); (E, 4); (F, 5); (Gb, 6); (G, 7); (Ab, 8); (A, 9); (Bb, 10); (B, 11)]; [(G, 0); (Ab, 1); (A, 2); (Bb, 3); (B, 4); (C, 5); (Db, 6); (D, 7); (Eb, 8); (E, 9); (F, 10); (Gb, 11)]]
ここでは11フレットまでしか用意しませんでしたが、もちろんもっと用意してもかまいません。
ユーティリティ関数として (A, 0) などのポジションと [C; E; G] というコードが与えられたときに A がコード [C; E; G] の構成音かどうかを判定する関数を用意しておきます。position -> chord -> bool です。
let is_chord_tone (tone, _) chord = List.mem tone chord
今回のコード探索プログラムは「クロージャを作成して、そのクロージャを呼び出すたびにコードフォームの候補を次々返してくれる」というものにします。そのクロージャは unit -> form で、呼び出す度に [(G, 0); (C, 0); (E, 0); (C, 3)] とか [(G, 0); (C, 0); (E, 0); (E, 7)] を返してくれるイメージです。
クロージャを作り出すための関数を次のように定義しました。
let create_form_finder strings chord_to_find filters =
let agenda = Queue.create () in
let rec find () =
let state = Queue.take agenda in
match state with
| (form, []) -> if List.for_all (fun p -> p form) filters then form else find ()
| (form, (position :: string) :: strings) ->
if (is_chord_tone position chord_to_find) then
(Queue.push (position :: form, strings) agenda;
Queue.push (form, string :: strings) agenda;
find ())
else
(Queue.push (form, string :: strings) agenda;
find ())
| (_, [] :: _) -> find ()
in
Queue.push ([], strings) agenda;
find
まず引数です。
let create_form_finder strings chord_to_find filters =
strings : string_ list には先ほど定義した strings を与えます。変則チューニングにも対応できるように引数にしました。chord_to_find : chord は見つけたいコードです。filters : (form -> bool) list は検索するコードフォームをフィルタリングする条件を与えます。複数指定できるようにリストにしました。
let agenda = Queue.create () in
agenda : state Queue.t には探索中の状態が入ります。state は type state = form * string_ list と定義しましたが「これまでに押さえたポジション * まだ押さえていない弦」という意味になります。
let rec find () =
let state = Queue.take agenda in
match state with
コード探索クロージャの中ではまず agenda から状態をひとつとって、その状態の内容で進み方を決めます。
まず「すでに全ての弦を押さえていて、コードフォームになっている」という場合です。
| (form, []) -> if List.for_all (fun p -> p form) filters then form else find ()
この場合、フィルタリング条件を適用して OK だったらコードフォームを返します。だめだったら探索を続けます。
次のケースはまだ全ての弦を押さえていない途中のケースです。
| (form, (position :: string) :: strings) ->
このケースは「残りの最初の弦の一番低いポジション」がコードの構成音かどうかで場合分けします。
if (is_chord_tone position chord_to_find) then
(Queue.push (position :: form, strings) agenda;
Queue.push (form, string :: strings) agenda;
find ())
構成音だった場合「そのポジションを押さえる」か「そのポジションは押さえずにもっと高いポジションを押さえるか」という2通りの行き先があります。これは先の C コードの例で言うと1弦3フレットが構成音だけど3フレットを押さえるか、もっと先(7フレット)を押さえるかというようなことです。1つ目の push は押さえるほうの分岐で、フォームにポジションを追加して残りの弦を減らします。2つ目の push は押さえない判断で、フォームはそのままで弦の最低ポジションを捨てます(次のフレットが次回 agenda から取られるときの最低ポジションになります)。
else
(Queue.push (form, string :: strings) agenda;
find ())
構成音ではなかった場合はフォームはそのままで弦の最低ポジションを捨てます。
| (_, [] :: _) -> find ()
今回の定義では各弦について11フレット目までしかポジションを定義していないので、最低ポジションを捨て続けて11フレットまでを使い切ったら「詰み」になります。
in Queue.push ([], strings) agenda; find
初期状態として「まだどこも押さえていなくて4弦すべて残っている状態」をキューに入れ、クロージャを返しています。
とりあえずこの状態で使ってみましょう。
# let find = create_form_finder strings [C; E; G] [];; val find : unit -> (note * int) list = <fun> # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (G, 3); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (E, 4); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (E, 7)]
1弦3フレットを押さえる C や 1弦7フレットを押さえる C を見つけてくれています。一方で2つ目の結果のように C と G だけで E が入っていないフォームも結果に含まれています。「完全なコード」だけを検出するように追加条件を指定したいと思います。
let is_complete_chord chord form = let tone_included tone = List.exists (fun (t, _) -> t = tone) form in List.for_all tone_included chord
これを指定すると次のような結果になります。
# let find = create_form_finder strings [C; E; G] [is_complete_chord [C; E; G]];; val find : unit -> (note * int) list = <fun> # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (E, 4); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (E, 7)]
不完全なコードを除外してくれるようになりました。なお「最初から不完全なコードを除外するように create_chord_finder を書けばいいのでは?」と思うかもしれませんが、ウクレレでは不完全なコードを使うことも結構あるため(例えば D7=D+F#+A+C のコードに対して A+F#+C+A で押さえることも多い)、追加条件で指定する仕様にしました。
ところで、コード検出を続行すると次のようなフォームを検出します。
# find ();; - : (note * int) list = [(G, 0); (G, 7); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (E, 4); (G, 3); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (G, 3); (E, 7)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (G, 10)] # find ();; - : (note * int) list = [(C, 5); (G, 7); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(E, 9); (C, 0); (G, 3); (C, 3)]
3フレット目と9フレット目を同時に押さえるというのは無理ですね。3と7もすこし遠いかもしれません。押弦している最低フレットと最高フレットの差を3フレットまでに限定してみます。
let is_possible_form form =
let non_open = List.filter (fun (_, fret) -> fret <> 0) form in
match non_open with
| [] -> true
| _ :: [] -> true
| (_, fret) :: ps ->
let (min_, max_) =
List.fold_left
(fun (min_, max_) (_, fret) -> (min min_ fret, max max_ fret))
(fret, fret)
ps
in
(max_ - min_) < 4
この条件を追加すると11フレット目までの全ての C コードは以下のとおりとなります。
# let find = create_form_finder strings [C; E; G] [is_complete_chord [C; E; G]; is_possible_form];; val find : unit -> (note * int) list = <fun> # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (E, 4); (E, 0); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (E, 7)] # find ();; - : (note * int) list = [(G, 0); (E, 4); (G, 3); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (E, 0); (G, 10)] # find ();; - : (note * int) list = [(C, 5); (E, 4); (G, 3); (C, 3)] # find ();; - : (note * int) list = [(G, 0); (C, 0); (C, 8); (E, 7)] # find ();; - : (note * int) list = [(C, 5); (G, 7); (E, 0); (E, 7)] # find ();; - : (note * int) list = [(E, 9); (C, 0); (E, 0); (G, 10)] # find ();; - : (note * int) list = [(G, 0); (G, 7); (C, 8); (E, 7)] # find ();; - : (note * int) list = [(C, 5); (G, 7); (C, 8); (E, 7)] # find ();; - : (note * int) list = [(E, 9); (C, 0); (C, 8); (G, 10)] # find ();; - : (note * int) list = [(E, 9); (G, 7); (C, 8); (E, 7)] # find ();; - : (note * int) list = [(E, 9); (G, 7); (C, 8); (G, 10)] # find ();; Exception: Queue.Empty.
偶数か奇数かを静的に型チェックする [OCaml]
PAIP 本 p.27 の「静的型付けの言語でも偶数を期待する関数に奇数を渡すのをチェックしてくれるわけではない」に関連して、以下のような OCaml モジュールを書いた。
(* oddeven.mli *)
type 'a t constraint 'a = [< `Even | `Odd ]
val zero : [`Even] t
val one : [`Odd] t
val make_even : int -> [`Even] t
val make_odd : int -> [`Odd] t
val to_int : 'a t -> int
val succ : 'a t -> 'a t
val pred : 'a t -> 'a t
val succ_odd : [`Even] t -> [`Odd] t
val pred_odd : [`Even] t -> [`Odd] t
val succ_even : [`Odd] t -> [`Even] t
val pred_even : [`Odd] t -> [`Even] t
val ( +$ ) : 'a t -> 'a t -> [`Even] t
val ( -$ ) : 'a t -> 'a t -> [`Even] t
val ( *$ ) : 'a t -> 'a t -> 'a t
val ( /$ ) : 'a t -> 'a t -> int
val print : Format.formatter -> 'a t -> unit(* oddeven.ml *)
type 'a t = int constraint 'a = [< `Even | `Odd ]
let zero = 0
let one = 1
let make_even i =
if i mod 2 = 0 then i
else raise (Invalid_argument "must be even integer")
let make_odd i =
if abs (i mod 2) = 1 then i
else raise (Invalid_argument "must be odd integer")
let to_int i = i
let succ i = i + 2
let pred i = i - 2
let succ_odd i = i + 1
let pred_odd i = i - 1
let succ_even i = i + 1
let pred_even i = i - 1
let ( +$ ) m n = m + n
let ( -$ ) m n = m - n
let ( *$ ) m n = m * n
let ( /$ ) m n = m / n
let print p i = Format.print_string (string_of_int i)
このようにすると、
# #load "oddeven.cmo";; # open Oddeven;; # #install_printer print;; # zero;; - : [ `Even ] Oddeven.t = 0 # one;; - : [ `Odd ] Oddeven.t = 1 # let two = make_even 2;; val two : [ `Even ] Oddeven.t = 2 # let three = succ one;; val three : [ `Odd ] Oddeven.t = 3 # let four = one +$ three;; val four : [ `Even ] Oddeven.t = 4 # let five = succ_odd four;; val five : [ `Odd ] Oddeven.t = 5 # succ_odd five;; This expression has type [ `Odd ] Oddeven.t but is here used with type [ `Even ] Oddeven.t These two variant types have no intersection
というわけで偶数を期待する succ_odd に奇数を渡したときにコンパイル時エラーとなる。
ただこのモジュールは偶数か奇数かが同じもの同士の演算しか定義していなくて、そうじゃない場合まで考えるとなんか面倒になりそう。
細かいことを考えなければ
val add : 'a t -> 'b t -> int
みたいになるけど、これは全然うれしくなくて、例えば任意の整数に偶数を足しても偶数か奇数かは変わらないということを考慮したければ、
val add_even : 'a t -> [`Even] t -> 'a t
となって、交換法則があるのでさらに、
val even_add : [`Even] t -> 'a t -> 'a t
とか、こうした1つ1つを適宜使い分けていくというのはさすがにどうか。何かうまい方法があるのだろうか。
もう一つ問題は Oddeven.t 型の値のコンストラクタとして make_even と make_odd を用意したけど、これに間違った値が来た場合のエラーは実行時にせざるを得ない。
それは引数がリテラルのようにコンパイル時に決定されている場合でも同様で、
# make_even 7;; Exception: Invalid_argument "must be even integer".
となる。7 は int のリテラルなのであって Oddeven.t のリテラルじゃないんだからしょうがない。以前も少し書いたけど抽象データ型とリテラルはお互いにうまく溶け合わないってことになるんだろうか。
OCaml + sexplib で Scheme もどきを作る [OCaml]
よく Scheme や Lisp の本で Scheme/Lisp を使って Scheme/Lisp 処理系を書くというのがあって大層簡潔に書いてあったりするのですが、これは要するに S 式リーダ機能がビルトインで存在するというのが有利に働いているので、他の言語でも S 式を簡単に読めれば同じくらいにはできそうです。
そこで OCaml の sexplib [1] を使ってみたかったこともあって、それを使ってなんちゃって Scheme を書いてみました。
なお sexplib は「産業界における関数型言語の事例」でよく引き合いに出されている Jane Street Capital で開発された OCaml 向けの S 式ライブラリです。
#use "topfind";;
#require "sexplib";;
#require "extlib";;
open ExtList;;
open Sexplib;;
open Sexplib.Sexp;;
module Data = struct
type t = Int of int | Bool of bool | Closure of (t list -> t)
let show = function
| Int x -> print_int x; print_newline ()
| Bool true -> print_endline "#t"
| Bool false -> print_endline "#f"
| Closure _ -> print_endline "#<closure>"
end
module Env = struct
type rib = string list * Data.t array
type t = rib list
let globals = Hashtbl.create 256
let set_global id v = (Hashtbl.replace globals id v; v)
let get_global id = Hashtbl.find globals id
let empty_env : t = []
let rec apply_env x = function
| [] -> get_global x
| (ids, vals)::rs ->
try
let (pos, _) = List.findi (fun _ y -> x = y) ids in
vals.(pos)
with Not_found -> apply_env x rs
let extend_env ids vals env =
(ids, Array.of_list vals)::env
let rec set_var id v = function
| [] -> set_global id v
| (ids, vals)::rs ->
try
let (pos, _) = List.findi (fun _ y -> id = y) ids in
(vals.(pos) <- v; v)
with Not_found -> set_var id v rs
end
open Data;; open Env;;
let is_integer x = try (ignore (int_of_string x); true) with Failure _ -> false
let rec interp x env =
match x with
| Atom "#t" -> Bool true
| Atom "#f" -> Bool false
| Atom x when is_integer x -> Int (int_of_string x)
| Atom x -> apply_env x env
| List (Atom "begin" :: xs) ->
let results = List.map (fun y -> interp y env) xs in
List.last results
| List [Atom "set!"; Atom x; y] ->
set_var x (interp y env) env
| List [Atom "if"; cond; true_exp; false_exp] ->
(match (interp cond env) with
| Bool false -> interp false_exp env
| _ -> interp true_exp env
)
| List (Atom "lambda" :: List ids :: body) ->
let closure args =
let ids = List.map (function Atom x -> x) ids in
let new_env = extend_env ids args env in
let results = List.map (fun y -> interp y new_env) body in
List.last results
in
Closure closure
| List (x :: xs) ->
let Closure f = interp x env in
f (List.map (fun y -> interp y env) xs)
let procs = [
("+", fun [Int a; Int b] -> Int (a + b));
("-", fun [Int a; Int b] -> Int (a - b));
("*", fun [Int a; Int b] -> Int (a * b));
("/", fun [Int a; Int b] -> Int (a / b));
("=", fun [Int a; Int b] -> Bool (a = b));
("<", fun [Int a; Int b] -> Bool (a < b));
(">", fun [Int a; Int b] -> Bool (a > b));
("<=", fun [Int a; Int b] -> Bool (a <= b));
(">=", fun [Int a; Int b] -> Bool (a >= b));
]
let init_interp () =
List.iter (fun (name, f) -> ignore (set_global name (Closure f))) procs
let repl () =
init_interp ();
while true do
print_string "=> ";
let input = read_line () in
show (interp (Sexp.of_string input) [])
done
ちょうど100行くらいでなかなかいい感じではないでしょうか。
この Scheme もどきが扱うデータは Data.t 型で定義されているように整数と真偽値とクロージャのみです。文字列も扱いたかったのですが sexplib ではシンボルと文字列、例えば (a b c) と ("a" "b" "c") を区別できなかったのであきらめました。これは sexplib の限界です。
環境は EOPL でもやったようなオーソドックスな rib cage 実装で、大域変数のためにハッシュテーブルも使っています。
使用例は以下の通りです。
# repl ();; => (set! double (lambda (x) (+ x x))) #<closure> => (double 45) 90 => ((if (= 1 2) * +) 3 4) 7 => ((if (= 1 1) * +) 3 4) 12 => (set! fact (lambda (n) (if (= n 0) 1 (* n (fact (- n 1)))))) #<closure> => (fact 5) 120 => (set! counter ((lambda (c) (lambda (n) (set! c (+ c n)))) 0)) #<closure> => counter #<closure> => (counter 1) 1 => (counter 1) 2 => (counter 4) 6 => (counter 2) 8
[1] http://www.ocaml.info/home/ocaml_sources.html#toc9
入力値をソートするプログラムを Camlp4 で生成 [OCaml]
どう書くorgの問題の回答なのだけど今サイトが落ちてるみたいなのでこっちの記事にしてしまうことにしました。「『ユーザからの整数の入力を変数に入れてそれらを if だけでソートするプログラム』を生成するプログラムを書け」という問題です。既に投稿されていた shiro さんの Scheme のコードを参考にしつつ OCaml + Camlp4 3.9 で書きました。実は Camlp4 を使わないほうが楽に書けたのではないかという気も。
(*
#load "camlp4o.cma";;
#load "q_MLast.cmo";;
#load "pr_o.cmo";;
ocamlopt -pp 'camlp4o q_MLast.cmo' \
-I +camlp4 gramlib.cmxa camlp4.cmxa pa_o.cmx pr_o.cmx -o gensort gensort.ml
*)
let _loc = Token.dummy_loc;;
let var_of_int n = String.make 1 (char_of_int (n + 97));;
let vars n = Array.to_list (Array.init n var_of_int);;
let make_lid_list lids =
List.fold_right (fun x l -> <:expr< [$lid:x$ :: $l$] >>) lids <:expr< [] >>;;
let wrap_fun args e =
List.fold_right (fun x l -> <:expr< fun $lid:x$ -> $l$ >>) args e;;
let rec gencode sorted = function
| [] -> <:expr<
print_int_list $make_lid_list (List.rev sorted)$
>>
| u::us ->
let rec insert rs = function
| [] -> gencode (List.rev (u::rs)) us
| s::ss -> <:expr<
if $lid:s$ < $lid:u$ then
$(gencode (List.rev (u::rs) @ s::ss) us)$
else
$(insert (s::rs) ss)$
>>
in
insert [] sorted;;
let gensort n =
let vars = vars n in
let fmt = String.concat " " (Array.to_list (Array.make n "%d")) in
let e = gencode [] vars in
let f = wrap_fun vars e in
let s = <:str_item<
let print_int_list xs = do {
List.iter (fun x -> do {print_int x; print_string " "}) xs;
print_newline ()
}
in
Scanf.scanf $str:fmt$ $f$
>>
in
(!Pcaml.print_implem) [s, _loc];;
gensort (int_of_string Sys.argv.(1))
生成、コンパイル、実行の結果。
KURO-BOX% ocamlopt -pp 'camlp4o q_MLast.cmo' \ -I +camlp4 gramlib.cmxa camlp4.cmxa pa_o.cmx pr_o.cmx -o gensort gensort.ml KURO-BOX% for n in 1 2 3 4 5 6 7; do time ./gensort $n > a$n.ml; done ./gensort $n > a$n.ml 0.03s user 0.04s system 95% cpu 0.073 total ./gensort $n > a$n.ml 0.02s user 0.05s system 94% cpu 0.074 total ./gensort $n > a$n.ml 0.06s user 0.02s system 97% cpu 0.082 total ./gensort $n > a$n.ml 0.09s user 0.03s system 99% cpu 0.121 total ./gensort $n > a$n.ml 0.33s user 0.03s system 99% cpu 0.363 total ./gensort $n > a$n.ml 2.01s user 0.05s system 99% cpu 2.066 total ./gensort $n > a$n.ml 15.66s user 0.34s system 99% cpu 16.003 total KURO-BOX% for n in 1 2 3 4 5 6 7; do time ocamlc -o a$n a$n.ml; done ocamlc -o a$n a$n.ml 0.25s user 0.07s system 97% cpu 0.327 total ocamlc -o a$n a$n.ml 0.24s user 0.09s system 98% cpu 0.336 total ocamlc -o a$n a$n.ml 0.30s user 0.05s system 99% cpu 0.351 total ocamlc -o a$n a$n.ml 0.36s user 0.08s system 101% cpu 0.435 total ocamlc -o a$n a$n.ml 0.91s user 0.08s system 99% cpu 0.992 total ocamlc -o a$n a$n.ml 6.06s user 0.13s system 99% cpu 6.191 total ocamlc -o a$n a$n.ml 108.27s user 0.58s system 99% cpu 1:48.87 total KURO-BOX% ./a6 5 2 4 6 1 3 1 2 3 4 5 6
生成されるのはこんな感じのコード(値が3のとき)。
let _ =
let print_int_list xs =
List.iter (fun x -> print_int x; print_string " ") xs; print_newline ()
in
Scanf.scanf "%d %d %d"
(fun a b c ->
if a < b then
if b < c then print_int_list [a; b; c]
else if a < c then print_int_list [a; c; b]
else print_int_list [c; a; b]
else if a < c then print_int_list [b; a; c]
else if b < c then print_int_list [b; c; a]
else print_int_list [c; b; a])F# + Silverlight で Hello World (2) [OCaml]
XAML で定義したキャンバス上の部品に F# 側からアクセスするには Canvas の FindName メソッドを使えばいいようだ。
というわけで XAML を以下のように変更する。Greeting という名前のテキストブロックを追加したほか、MouseLeftButtonDown イベントで Page_MouseLeftButtonDown メソッドが呼ばれるように指定した。
<Canvas
xmlns="http://schemas.microsoft.com/client/2007"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
MouseLeftButtonDown="Page_MouseLeftButtonDown"
x:Class="SilverTest.Page;assembly=SilverTest.dll"
>
<TextBlock x:Name="Greeting">Hello Silverlight!</TextBlock>
</Canvas>
F# のほうではイベントに呼応して FindName を使って TextBlock を探し出して内容を書き換える。
namespace SilverTest
open System;
open System.Windows;
open System.Windows.Controls;
open System.Windows.Documents;
open System.Windows.Ink;
open System.Windows.Input;
open System.Windows.Media;
open System.Windows.Media.Animation;
open System.Windows.Shapes;
type Page = class inherit Canvas
new() = {}
member x.Page_MouseLeftButtonDown(o : obj, e : MouseEventArgs) =
let canvas = o :?> Canvas in
let text = canvas.FindName("Greeting") :?> TextBlock in
text.Text <- "I was pushed!!"
endF# + Silverlight で Hello World [OCaml]
とりあえず文字を表示するだけのものを作った。Silverlight は 1.1 Alpha Refresh が必要。
index.html を以下のように書く。Silverlight.js は SDK に含まれるものを置く。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
<head>
<script type="text/javascript" src="Silverlight.js"></script>
<title>Hello Silverlight!</title>
</head>
<body>
<!-- ここに Silverlight コントロールが表示されます -->
<div id="SilverlightControlHost"></div>
<script type="text/javascript">
// Silverlight コントロールをロードします
function createSilverlight()
{
Silverlight.createObjectEx({
source: 'Page.xaml',
parentElement:document.getElementById("SilverlightControlHost"),
id:'SilverlightControl',
properties:{
width:'200',
height:'200',
background:'silver',
isWindowless:'false',
framerate:'24',
enableFramerateCounter:'false',
version:'1.0'
},
events:{
onError:null,
onLoad:null,
onResize:null
},
context:null
});
}
createSilverlight();
</script>
</body>
</html>
Page.xaml は事実上の空。マネージドコードを使うので x:Class 属性にクラス名と DLL の場所を指定する。Loaded 属性で指定したメソッドがロード時に呼ばれる。
<Canvas
xmlns="http://schemas.microsoft.com/client/2007"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Loaded="Page_Loaded"
x:Class="SilverTest.Page;assembly=SilverTest.dll"
>
</Canvas>
SilverTest.fs が F# のコード。Page_Loaded で TextBlock オブジェクトを作ってキャンバスに追加する。[1] などを参照した。
namespace SilverTest
open System;
open System.Windows;
open System.Windows.Controls;
open System.Windows.Documents;
open System.Windows.Ink;
open System.Windows.Input;
open System.Windows.Media;
open System.Windows.Media.Animation;
open System.Windows.Shapes;
type Page = class inherit Canvas
new() = {}
member x.Page_Loaded(o : obj, e : EventArgs) =
let canvas = o :?> Canvas in
let text = new TextBlock() in
text.Text <- "Hello Silverlight!!";
text.SetValue(Canvas.TopProperty, 0);
text.SetValue(Canvas.LeftProperty, 0);
canvas.Children.Add(text);
end
コンパイルオプション。[2] に書いてあったのをほぼそのまま使った。
fsc -r System.SilverLight.dll -r agclr.dll -r Microsoft.Scripting.Vestigial.dll -r System.dll -r Microsoft.Scripting.Silverlight.dll -r Microsoft.Scripting.dll --clr-root "C:\Program Files\Microsoft Silverlight" --no-framework --no-mllib --static-link fslib -a SilverTest.fs
XAML で定義したキャンバス上のオブジェクトを F# 側から触る方法がまだ分からなくて、何も出来ていないようなものだ。C# のサンプルなんかでは何もしなくても名前で指定できてるっぽいんだけど。あと F# のクラス構文もまだ全然わかってない。
[1] http://www.strangelights.com/blog/archive/2007/05/25/1584.aspx
[2] http://www.strangelights.com/blog/archive/2007/05/28/1585.aspx
OCaml で正規表現エンジンを作る [OCaml]
結構前にブックマークして後でちゃんと読もうと思ってた「Regular Expression Matching Can Be Simple And Fast」という記事 [1] があるのだけど、それを参考にして OCaml で正規表現エンジンを作ってみました。
type state =
| Char of char * state ref
| Split of state ref * state ref
| Match
type frag = {nfa: state; danglings: state ref list}
let post_of_regex regex =
let rec expr = parser
| [< c = conc; t = expr_tail >] -> c ^ t
and expr_tail = parser
| [< ''|'; c = conc; t = expr_tail >] -> c ^ "|" ^ t
| [< >] -> ""
and conc = parser
| [< r = rept; t = conc_tail >] -> r ^ t
and conc_tail = parser
| [< r = rept; t = conc_tail >] -> r ^ "." ^ t
| [< >] -> ""
and rept = parser
| [< a = atom; t = rept_tail >] -> a ^ t
and rept_tail = parser
| [< ''?' >] -> "?"
| [< ''*' >] -> "*"
| [< ''+' >] -> "+"
| [< >] -> ""
and atom = parser
| [< ''('; e = expr; '')' >] -> e
| [< ''a'..'z' as c>] -> String.make 1 c
in
expr (Stream.of_string regex)
let patch l s = List.iter (fun o -> o := s) l
let rec nfa_of_post' frags = parser
| [<''.'; strm>] ->
let e2::e1::rest = frags in
let frags = {nfa = e1.nfa; danglings = e2.danglings}::rest in
patch (e1.danglings) e2.nfa;
nfa_of_post' frags strm
| [<''|'; strm>] ->
let e2::e1::rest = frags in
let out1 = ref e1.nfa in
let out2 = ref e2.nfa in
let nfa = Split (out1, out2) in
let danglings = e1.danglings @ e2.danglings in
let frags = {nfa = nfa; danglings = danglings}::rest in
nfa_of_post' frags strm
| [<''?'; strm>] ->
let e::rest = frags in
let out1 = ref e.nfa in
let out2 = ref Match in
let nfa = Split (out1, out2) in
let danglings = out2 :: e.danglings in
let frags = {nfa = nfa; danglings = danglings}::rest in
nfa_of_post' frags strm
| [<''*'; strm>] ->
let e::rest = frags in
let out1 = ref e.nfa in
let out2 = ref Match in
let nfa = Split (out1, out2) in
let frags = {nfa = nfa; danglings = [out2]}::rest in
patch (e.danglings) nfa;
nfa_of_post' frags strm
| [<''+'; strm>] ->
let e::rest = frags in
let out1 = ref e.nfa in
let out2 = ref Match in
let nfa = Split (out1, out2) in
let frags = {nfa = e.nfa; danglings = [out2]}::rest in
patch (e.danglings) nfa;
nfa_of_post' frags strm
| [<'c; strm>] ->
let out = ref Match in
let nfa = Char (c, out) in
let frags = {nfa = nfa; danglings = [out]}::frags in
nfa_of_post' frags strm
| [< >] -> (List.hd frags).nfa
let nfa_of_post post =
nfa_of_post' [] (Stream.of_string post)
let rec add_state state states =
if List.mem state states then states
else
match state with
| Split (out1, out2) -> add_state !out1 (add_state !out2 states)
| _ -> state::states
let step c states =
let rec filter acc = function
| Char (c', out) -> if c = c' then (add_state !out acc) else acc
| _ -> acc
in
List.fold_left filter [] states
let rec matching states = parser
| [<'c; strm>] -> matching (step c states) strm
| [< >] -> states
let match_regex regex s =
let post = post_of_regex regex in
let start = nfa_of_post post in
let result = matching (add_state start []) (Stream.of_string s) in
List.mem Match result
let _ =
let regex = Sys.argv.(1) in
for i = 2 to pred (Array.length Sys.argv) do
if match_regex regex Sys.argv.(i)
then print_endline Sys.argv.(i)
done
まず post_of_regex 関数で正規表現を後置記法に変換します。これはドットを「連結」の意味に使うもので、たとえば ab?cd は ab?.c.d. になって a(bc)+d は abc.+.d. になります。
nfa_of_post 関数でその後置記法正規表現から NFA という構造に変換します。これは [1] の図を参照。NFA を表現するデータ型を state 型として定義しています。変換の過程で NFA の断片とその断片中の行き先がまだ決まっていない矢印をセットで扱うために frag 型を定義しています。patch 関数でそうした矢印の先を行き先に結びつけます。
そのようにしてできた NFA を使って実際にマッチングを行うのが matching 関数で、これは入力の各文字について期待される文字とマッチしているかどうかを確認していくのですが、NFA が分岐する場合は分岐した状態をパラレルに保持しながらステップを進めていきます。
さて [1] の記事の強く主張するところは、このやり方は Perl をはじめとする多くのスクリプト言語で採用されているものよりもずっと速い(というか難しい正規表現でも速度が劣化しにくい)、ということなのだけど、この正規表現エンジンはどうだろうか。というわけで [1] の記事で使われているのと同じスクリプトを使って計測してグラフにしてみました。
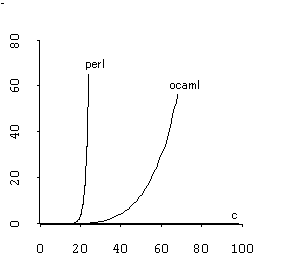
グラフ中の perl が Perl で、私の作ったのが ocaml で、元記事のプログラムが c です。Perl 程ではないけど元記事のプログラムより断然性能劣化が早いという残念な結果に。んーなんかまずいことをしてしまってる部分があるんだろうなあ。とりあえずちゃんと動く正規表現エンジンが書けたというだけで満足気味なので今はもうこれでいいや。
ところで [1] の中ごろのグラフを見ると私の好きな Tcl は実は正規表現がかなり良い結果だということがわかります。The Computer Language Benchmarks Game というサイトで普通 Tcl は軒並み下位なんですが regex-dna という問題だけはかなりの上位 [2] だったのを以前見て疑問に思ってたんですが、そういうわけだったのかと。
[1] http://swtch.com/~rsc/regexp/regexp1.html
[2] http://shootout.alioth.debian.org/debian/benchmark.php?test=regexdna&lang=all
ether さん

-
nice! 34
記事 322
テーマ パソコン・インターネット
プロフィール
ブログを紹介する
--



