Ruby による LFG [Ruby]
Bresnan の書いた LFG (Lexical Functional Grammar) の入門テキスト "Lexical Functional Syntax" の最初の方を読んだ。これが面白かったので Ruby による実装に挑戦してみた。
* 速習 LFG
LFG は Chomsky 流の生成文法とは違ってひとつの文についてひとつの統語表示だけを与える。その代わりに統語表示以外にもいくつかの構造を利用していて、マッピングルールによってそれらを結びつける(「変形」や「移動」ではない)という考え方をとっている。
最も基本となる構造は c-structure と f-structure で、前者はいわゆる統語構造(c は constituent)で後者は主語や目的語といった文法概念が登場する素性構造(f は feature または function)である。
見るが早しということで例を挙げると "Lions sleep." という文には以下のような c-structure と f-structure が与えられる。
c-structure:
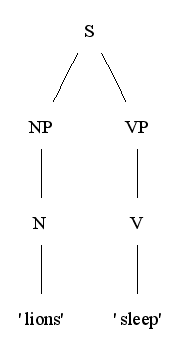
f-structure:
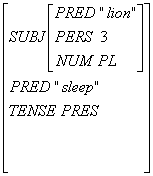
c-structure はツリー構造、f-structure はプログラミング言語でいうところの連想配列の構造を持つが、階層的になっていてもよい。
c-structure から f-structure へのマッピングルールは文脈自由法の個々の置き換え規則および単語の辞書内に以下のように記載された等式群を利用する(この文法はもちろん部分的なもの)。

「↑ = ↓」は大体「上位ノードに対応付けられる f-structure とこのノードに対応づけられる f-structure が同じ」と読む。「(↑ SUBJ) = ↓」は「上位ノードに対応付けられる f-structure の SUBJ 素性の値がこのノードに対応づけられる f-structure である」。そして「(↑ NUM) = PL」は「上位ノードに対応付けられる f-structure の NUM 素性の値が PL である」、などなど。
"Lions sleep." の c-structure のノードにそれぞれ対応付けられる f-structure の名前を付与してみよう。
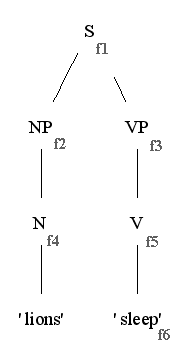
これにしたがって先ほどの等式群を置き換えると以下のような等式群が得られる。
(f1 SUBJ) = f2 f1 = f3 f2 = f4 f3 = f5 (f4 PRED) = 'lion' (f4 NUM) = PL (f5 PRED) = 'sleep' (f5 TENSE) = PRES (f5 SUBJ) = f6 (f6 PERS) = 3 (f6 NUM) = PL
この等式を順番に解決していくと以下のようになる。
(f1 SUBJ) = f2
f1 = f3
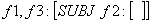
f2 = f4
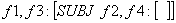
f3 = f5
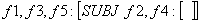
(f4 PRED) = 'lion'
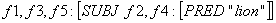
(f4 NUM) = PL
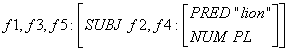
(f5 PRED) = 'sleep'
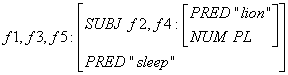
(f5 TENSE) = PRES

(f5 SUBJ) = f6

(f6 PERS) = 3 および (f6 NUM) = PL
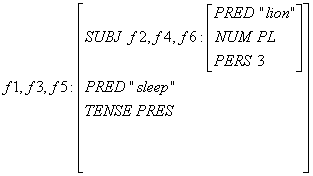
結果として目的の f-structure が出来上がっていることがわかる。
最後の (f6 NUM) = PL を解決するところで f2=f4=f6 の NUM にはすでに PL が埋まっていることに注目されたい。この場所に同じ PL がくるためにこれらの等式は矛盾なく成立するということになる。
これが "*Lions sleeps." のような非文の場合、sleeps の辞書には (↑ NUM) = PL の代わりに (↑ NUM) = SG が登録されている。そうすると最後の部分ですでに作られている構造と矛盾することになってこの文は成立しない。LFG ではこのようにしていわゆる数の一致が説明できる。
* 実装
インターネットで検索すると LFG の実装がいくつかみつかるが、どれも Prolog を使っているようだ。私は Prolog はさっぱり(いつか習得したいけど)なので代わりに Ruby を用いたい。Ruby だとハッシュが使えるので素性構造の表現もしやすそうだ(今回はオブジェクト指向はほとんど使わない)。
等式の解決はいわゆる単一化と呼ばれるもので、Reasoned Schemer の "Under the hood" の章の Scheme 実装を参考にした。
** 環境
f1 = f3 と f3 = f5 がすでに与えられているときに、「f1 の値は?」と「f3 の値は?」と「f5 の値は?」という質問には同じ答えを与えなければならない。このように何と何が同じという知識を蓄えるデータベースが必要だ。このデータベース(環境)は変数から値へのハッシュとして表現できる。変数の値がさらに別の変数だったらもう1回その別の変数の値を探すことによって上記の要件を満たすことができる。
class Var; end
# 環境sを元に変数vの値を返す。vが未束縛の場合はvを返す。
def walk(v, s)
if v.kind_of?(Var) then
a = s[v]
if a then
return walk(a, s)
else
return v
end
else
return v
end
end
Var は変数をあらわすクラスで、これは「変数である」という判定ができるオブジェクトであればなんでもよいので定義は空である。Ruby では kind_of? メソッドでクラスの判定ができる。walk メソッドは環境 s に基づいて与えられた変数の値を返すが、値が変数だった場合はその変数をもとに再帰的に値を検索していく。結局未定義だった場合は変数そのままで返す。
**単一化
等式がひとつひとつ与えられる段階ではこの環境をどんどん拡張していくことになる。まずは単純にハッシュを拡張するためのメソッド。
# x→vでsを拡張して返す(非破壊的)
def ext_s(x, v, s)
new_s = s.clone
new_s[x] = v
return new_s
end
これを使って単一化をするためのメソッドは以下。
# 環境sにおいてvとwを単一化して新しい環境sを返す
# 単一化できなければnil
def unify_s(v, w, s)
return nil unless s
v = walk(v, s)
w = walk(w, s)
case
when v.equal?(w) then return s
when v.kind_of?(Var) then return ext_s(v, w, s)
when w.kind_of?(Var) then return ext_s(w, v, s)
when v.kind_of?(Hash) && w.kind_of?(Hash) then
v.each{|key, value| if w[key] == nil then w[key] = value end}
w.each{|key, value| if v[key] == nil then v[key] = value end}
return v.inject(s){|new_s, pair| unify_s(pair[1], w[pair[0]], new_s)}
when v == w then return s
end
end
v と w は最初に walk にかけて正規化する。その上で v = w であればそのままの環境、どちらかが変数であれば新しいバインディングを追加した環境を返す。このへんは Reasoned Schemer そのまま。
付け加えたのは共にハッシュだった場合の処理で、この場合はお互いに足りないキーの値を埋めてあげた後で個々の値を単一化している。これは {:NUM=>:PL} と {:NUM=>:SG} は矛盾しないといけないが、{:PRED=>'lion'} と {:NUM=>:PL} は単一化に成功する必要があるためだ。(この辺の処理が破壊的操作になっているのがいまいちな気もするけど他にやりようがあるのかよくわからない)
(f1 SUBJ) = f2 のような形式の単一化のためのメソッドも作った。
def lookup_o(h, k, v, s)
return nil unless s
h = walk(h, s)
v = walk(v, s)
case h
when Var then
ext_s(h, {k=>v}, s)
when Hash then
if h[k] != nil then
return unify_s(h[k], v, s)
else
# destructive
h[k] = v
return s
end
else
return
end
end
** 文法と辞書
残すは文法と辞書。c-structure は以下のような形式で与えられるものとする。
c_structure = [:S, [:NP, [:N, "lions"]], [:VP, [:V, "sleep"]]]
文法と辞書に対応するものがこれ。
class Array
def rest
return self[1..-1]
end
end
def match(s, lhs, rhs)
case rhs
when Array then
return s[0] == lhs && s.rest.map{|x| x[0]} == rhs
else
return s[0] == lhs && s[1] == rhs
end
end
def c2f(c, s, up)
case
when match(c, :S, [:NP, :VP]) then
np = Var.new
vp = Var.new
s = lookup_o(up, :SUBJ, np, s)
s = unify_s(up, vp, s)
s = c2f(c[1], s, np)
s = c2f(c[2], s, vp)
return s
when match(c, :NP, [:N]) then
down = Var.new
s = unify_s(up, down, s)
s = c2f(c[1], s, down)
return s
when match(c, :VP, [:V]) then
down = Var.new
s = unify_s(up, down, s)
s = c2f(c[1], s, down)
return s
when match(c, :N, "lions") then
s = lookup_o(up, :PRED, "lion", s)
s = lookup_o(up, :NUM, :PL, s)
return s
when match(c, :V, "sleep") then
s = lookup_o(up, :PRED, "live", s)
s = lookup_o(up, :TENSE, :PRES, s)
down = Var.new
s = lookup_o(up, :SUBJ, down, s)
s = lookup_o(down, :NUM, :PL, s)
s = lookup_o(down, :PERS, 3, s)
return s
when match(c, :V, "sleeps") then
s = lookup_o(up, :PRED, "live", s)
s = lookup_o(up, :TENSE, :PRES, s)
down = Var.new
s = lookup_o(up, :SUBJ, down, s)
s = lookup_o(down, :NUM, :SG, s)
s = lookup_o(down, :PERS, 3, s)
return s
end
end
ここは我ながら汚すぎてどうかと思うけど、本当ならもうちょっとデータ駆動な感じであるべきところ。
** 実行と pretty printing
この c2f メソッドを使って以下のようにするとすべての等式が解決された環境が得られる。
top_f = Var.new
s = c2f(c_structure, {}, top_f)
なお、ここで p s[top_f] とか p walk(top_f, s) とやっても以下のような表示になってしまう。
{:TENSE=>:PRES, :SUBJ=>#<Var:0x293b0c8>, :PRED=>"live"}
つまりハッシュの中に Var クラスのオブジェクトが出てくる場合はそれも環境に照らして walk したものを表示してあげる必要がある。
def walk_star(v, s)
v = walk(v, s)
case v
when Var then return v
when Hash then
return v.inject({}){|hsh, pair|
hsh[pair[0]] = walk_star(pair[1], s)
hsh
}
else return v
end
end
p walk_star(top_f, s) if s
この walk_star メソッドをつかうと無事以下のような結果が得られる。
{:TENSE=>:PRES, :SUBJ=>{:NUM=>:PL, :PERS=>3, :PRED=>"lion"}, :PRED=>"live"}
一方で "Lions sleeps." を与えると s は nil になり、単一化は失敗する。
c_structure = [:S, [:NP, [:N, "lions"]], [:VP, [:V, "sleeps"]]]
top_f = Var.new
s = c2f(c_structure, {}, top_f)
p walk_star(top_f, s) if s
2007-04-10追記:
上記のプログラムにはバグがあった。問題は Hash を単一化する部分で、これは以下のような例でうまくいかない。
f1 = Var.new
f2 = Var.new
f3 = Var.new
s = {}
s = lookup_o(f1, :A, 1, s)
s = lookup_o(f2, :B, 2, s)
s = lookup_o(f3, :C, 3, s)
p s
s = unify_s(f1, f2, s)
s = unify_s(f1, f3, s)
p s
p walk(f1, s)
p walk(f2, s)
p walk(f3, s)
この例だと f1=f2=f3 なので最後の3つはどれも {:A=>1, :B=>2, :C=>3} になってほしいところだが実際には f2 だけ {:A=>1, :B=>2} となる。f1 と f2 の単一化で両者のハッシュを互いに埋め合わせたのはいいが、実体としては別オブジェクトのままなので f1 と f3 の単一化で f2 だけおいてけぼりになるのだ。これを直したつもりの unify_s は以下である。
def unify_s(v, w, s)
return nil unless s
v = walk(v, s)
w = walk(w, s)
case
when v.equal?(w) then return s
when v.kind_of?(Var) then return ext_s(v, w, s)
when w.kind_of?(Var) then return ext_s(w, v, s)
when v.kind_of?(Hash) && w.kind_of?(Hash) then
s = s.clone
new_h = v.merge(w) {|k, lhs, rhs|
s = unify_s(lhs, rhs, s)
lhs
}
return s.each{|key, val|
if val.equal?(v) or val.equal?(w) then s[key] = new_h end
}
when v == w then return s
end
endArray#index と String#index [Ruby]
前回のコード [1] を投稿した後でまずかったと思ったのは
pos = input[start..-1].index(pat.first)
とか書いている部分で、これは元の Lisp コードでいう
(let ((pos (position (first pat) input
:start start :test #'equal)))...
というのがやりたかった。
つまり配列 input の中で start 番目の要素以降に最初に pat.first が現れる位置を返すというものなのだけど Array#index [2] には探し始める位置を指定する引数が無いのでこうしたのだ。でも書き方の意図がすぐには分からないし配列を複製するので効率が悪い。あと pos に start を足さないと本来の位置が得られない。自家版 index メソッドを作った方が良かったと思う。
しかし String クラスの index メソッド [3] はどうだっけと思ってリファレンスを見たら、こっちはちゃんと検索開始位置を指定できることが判明。うーん、納得いかないなあ。(これを使う場面で最初に見つかるものだけに興味があるというほうが稀だと思うので基本的に index には開始位置が必須のような気がする)
[1] http://blog.so-net.ne.jp/rainyday/2007-03-18-1
[2] http://www.ruby-lang.org/ja/man/index.cgi?cmd=view;name=Array#index
[3] http://www.ruby-lang.org/ja/man/index.cgi?cmd=view;name=String#index
Ruby で配列のパターンマッチャーを書く [Ruby]
Norvig の PAIP を読みつつ p.154 あたりからのパターンマッチを Ruby に置き換えて書いてみた。オリジナルの Lisp のコードは [1] の前半部分。
配列の要素がシンボルの場合は(単一要素にマッチする)変数とみなし、要素が [:*, :x] のように最初が :* の配列の場合は segment variable とみなすという書き方にした。バインディングは勿論ハッシュとして返す。
class Array
def rest
return self[1..-1]
end
end
def var?(x)
return x.class == Symbol
end
def segment_pattern?(x)
Array === x && Array === x[0] && x[0][0] == :*
end
def pat_match(pattern, input, bindings = {})
case
when bindings == nil then
return nil
when var?(pattern) then
return match_var(pattern, input, bindings)
when pattern == input then
return bindings
when segment_pattern?(pattern) then
return segment_match(pattern, input, bindings)
when Array === pattern && Array === input then
return pat_match(pattern.rest, input.rest, pat_match(pattern.first, input.first, bindings))
else
return nil
end
end
def match_var(var, input, bindings)
if bindings == nil then return nil end
val = bindings[var]
case
when val == nil then
new_bindings = bindings.clone
new_bindings[var] = input
return new_bindings
when val == input then return bindings
else return nil
end
end
def segment_match(pattern, input, bindings, start = 0)
var = pattern[0][1] # :x in [[:*, :x], ...]
pat = pattern.rest
if pat == [] then
return match_var(var, input, bindings)
else
pos = input[start..-1].index(pat.first)
if pos == nil
return nil
else
b2 = pat_match(pat, input[(start+pos)..-1], match_var(var, input[0..(start+pos-1)], bindings))
if b2 == nil
return segment_match(pattern, input, bindings, pos+1)
else
return b2
end
end
end
end
以下は実行例。
p pat_match(["I", "need", "a", :x], "I need a vacation".split(/\s+/))
#=>{:x=>"vacation"}
p pat_match(["I", "need", "a", :x], "I really need a vacation".split(/\s+/))
#=>nil
p pat_match(["this", "is", "easy"], "this is easy".split(/\s+/))
#=>{}
p pat_match([:x, "is", :x], [[2, "+", 2], "is", 4])
#=>nil
p pat_match([:x, "is", :x], [[2, "+", 2], "is", [2, "+", 2]])
#=>{:x=>[2, "+", 2]}
p pat_match([[:*, :x], "need", [:*, :y]], "Mr. Hulot and I need a vacation".split(/\s+/))
#=>{:y=>["a", "vacation"], :x=>["Mr.", "Hulot", "and", "I"]}
p pat_match([[:*, :x], "is", "a", [:*, :y]], "What he is is a fool".split(/\s+/))
#=>{:y=>["fool"], :x=>["What", "he", "is"]}
p pat_match([[:*, :x], "a", "b", [:*, :x]], [1, 2, "a", "b", "a", "b", 1, 2, "a", "b"])
#=>{:x=>[1, 2, "a", "b"]}
case 構文がアルファベットが密集して読みづらいかなあと思った。return を書かないようにするのはよくない書き方だろうか。
あと Ruby の Array クラスはなんで(Lisp 由来であろう) first メソッドがあって rest メソッドがないんだろう。
[1] http://www.norvig.com/paip/eliza1.lisp
xlawk.rb: Excel 用の awk を Ruby で作る [Ruby]
私が Ruby を使う機会はもっぱら Win32OLE モジュールを使って Excel ブックを定型処理するような場合が多くなっています。
以前はこういう用途に Perl を使っていたのですが、よく使う「~の条件を満たすすべてのシートに対して~」というような処理はブロックを使った構文が書きやすいようです。
しかし構文がいくら書きやすくても結局いつも似たようなコードを書いているのに気づきます。Excel データに定型的な処理を行う場合に書くコードというのは大抵以下のようなものです。
1. 引数で与えられたすべてのブックに対して、
2. 中に入っているすべてのシートについて(何かの条件付きでフィルタして)、
3. シート中の最後の行までを(やはり何かの条件付きでフィルタして、データを変換したりしながら)走査する。
こうした処理というのは実は要するに awk であって、Excel に対する awk のようなものがあれば済む話なのです。
そんなわけで Excel ブックを対象に awk のような処理をするためのプログラムを Ruby で書きました。名前は xlawk.rb です。
コード
require 'win32ole'
class WIN32OLE
include Enumerable
def each_line()
lastcell = Cells().SpecialCells(Excel::XlLastCell)
(1..lastcell.Row).each{|row|
$ROW = row
line = Range(Cells(row, 1), Cells(row, lastcell.Column))
yield line.map{|cell| cell.Value}
}
end
end
module Excel; end
app = WIN32OLE.new('Excel.Application')
WIN32OLE.const_load(app, Excel)
app.visible = true
books = app.Workbooks;
prog = ARGV.shift
files = ARGV.inject([]){|product,pattern| product += Dir.glob(pattern).map{|file| File.expand_path(file)}}
files.each{|filename|
book = books.Open(filename)
$BOOK = book.Name
worksheets = book.Worksheets
worksheets.each{|sheet|
$SHEET = sheet.Name
sheet.each_line{|line|
$LINE = line
eval(prog)
}
}
book.Close()
}
app.Quit解説
上から解説していきます。
require 'win32ole'
これは Win32OLE モジュールを読み込んでいます。
class WIN32OLE
include Enumerable
def each_line()
lastcell = Cells().SpecialCells(Excel::XlLastCell)
(1..lastcell.Row).each{|row|
$ROW = row
line = Range(Cells(row, 1), Cells(row, lastcell.Column))
yield line.map{|cell| cell.Value}
}
end
end
前述の3つの定型処理のうち最初の2つは既にある道具立てで出来るのですが、Excel の API には行単位のコレクションというのはありません。
そこで WIN32OLE クラスに each_line メソッドというのを自家定義しています。ライブラリが提供する既存クラスに新たにメソッドを付け足せるというのが Ruby っぽくて面白いと思います。
行単位で繰り返すのに「どこで止めたらいいか」を知っておく必要があるため、 xlLastCell という特殊セルの場所を SpecialCells メソッドで取得しています。これは Excel で Ctrl+End を押したときに移動する先のセルのことです。
なお WIN32OLE クラスは each メソッドを提供しているので Enumerable モジュールもついでに include しています。
module Excel; end
app = WIN32OLE.new('Excel.Application')
WIN32OLE.const_load(app, Excel)
app.visible = true
books = app.Workbooks;
この辺りは Excel を使う上でのお決まりの前準備です。const_load は先の xlLastCell のような Excel の定数を使えるようにするためのものです。(Excel モジュールもそのためのものです)
アプリの Visible プロパティを true にするかどうかは好みがあると思いますが、途中で異常終了した場合に見えないけどプロセスが残っているという事態になりがちなので見えていたほうがいいと思います。
prog = ARGV.shift
files = ARGV.inject([]){|product,pattern| product += Dir.glob(pattern).map{|file| File.expand_path(file)}}
プログラムの第1引数は xlawk 用のコードで、第2引数以降が対象となる Excel ブック(ワイルドカード可)になります。
後でブックを開く時にはファイル名をフルパスを与える必要があるので、ファイル名パターンを glob で展開した後で File.expand_path を使ってフルパスを取得しています。
files.each{|filename|
book = books.Open(filename)
$BOOK = book.Name
worksheets = book.Worksheets
worksheets.each{|sheet|
$SHEET = sheet.Name
sheet.each_line{|line|
$LINE = line
eval(prog)
}
}
book.Close()
}
「すべてのファイルに対して(前述の1)~」が「files.each{|filename|」以降、
ファイルの「すべてのシートに対して(前述の2)~」が「worksheets.each{|sheet|」以降となります。
「すべての行に対して~」は先ほど定義した each_line メソッドを呼んでいます。このブロックの中で第1引数で与えられたプログラム片を eval します。
xlawk に与えるコードから便利に使えるようにいくつかのグローバル変数が定義されています。
$BOOK: 現在のブックの名前
$SHEET: 現在のシートの名前
$LINE: 現在の行のセルの内容が入った配列
$ROW: 現在の行番号
awk っぽく使うといっても評価されるコードは Ruby なので書き方には若干工夫が要ります。
awk で '$1 == "Foo" {print "Hit"}' と書くところを "($LINE[0] == 'Foo') and (puts 'Hit');" などと書くとまあまあそれっぽいと思います。
現実的な問題を解いてみましょう。例えば
・シート名が「目次」以外のシートにデータが入っている
・各シートの3行目からデータが開始する。
・2列目の内容候補は「A,B,C」のいずれかで他の値は入力ミス
というファイルについて入力ミスデータの箇所を探すコマンドは以下のように書けます。
ruby xlawk.rb "($SHEET != '目次') and ($ROW >= 3) and !(['A','B','C'].include? $LINE[1]) and (puts \"sheet:#{$SHEET}, row:#{$ROW}\")" data.xls
Ruby のシンボルについて [Ruby]
いまいちよく分かっていなかった Ruby のシンボルについて少し調べた。
「文字列とどう違うの?」という疑問の答えはこういうことらしい。
irb(main):001:0> "abc" == "abc"
=> true
irb(main):002:0> "abc".equal?("abc")
=> false
irb(main):003:0> :abc == :abc
=> true
irb(main):004:0> :abc.equal?(:abc)
=> true
== は表現を比較し、equal? はオブジェクトの同一性を比較する。文字列は同じ表現が同一の実体とは限らないけど同じ名前のシンボルは同じ実体である。
Ruby でシンボルが使われる典型的な例はハッシュのキー。
irb(main):010:0> {:key1 => "one", :key2 => "two"}
=> {:key1=>"one", :key2=>"two"}
でも文字列も普通に使えるし、キーの同一性についての振る舞いが違うということでもないようだ(ハッシュのキーはオブジェクトIDではなく表現で同一性が判断されているようだ)。ハッシュのキーによく使われるのはシンボルの内部表現が整数なので効率がいいというのが理由。
irb(main):012:0> {:key1 => "one", :key1 => "two"}
=> {:key1=>"two"}
irb(main):013:0> {"key1" => "one", "key1" => "two"}
=> {"key1"=>"two"}
リファレンスを眺めた限りでは Lisp の gensym のように既存のシンボルと重複しないシンボルを生成してくれるものはないようだ。
あと Ruby 内部では変数名をシンボルとして管理しているそうだけど、その変数テーブルへのアクセスの方法とかそういう辺りはよく分からなかった。できないのかもしれない。
ちなみに唐突にシンボルについて調べたのは、前回記事 [1] で思ったことの続きで、既存の変数と重複しない変数名を一時的に生成できれば「文脈に関わらずブロックローカルになる変数」を苦しいやりかたで実現できるかも、とちょっと思いついたという理由。まあ可能だったとしてもそんなイディオムは使いたくないと思うけど。
[1] http://blog.so-net.ne.jp/rainyday/2007-02-13
Ruby に let/local/my がない(らしい)ことについて [Ruby]
以前ブロックの仮引数がブロックの外側の同名の変数を指してしまうことについて書いた[1]。
でもこれは仮引数に限ったことではなくてブロックの中で使用される変数一般に言えることだ。
foo = lambda{
x = 2
}
このブロックの意味は定義された文脈で変数 x が可視であるかどうかによって変わる。
x が不可視であれば x はブロックローカルな変数だし、可視であればその x を指す(=その x を書き換える)。
だからブロックの中で使う変数は何であれそれがブロックが定義された文脈で定義済みかどうかを意識しておかなければならないということになる。
なんでこんなややこしいことになるんだろうと思ったら、良く考えたらこれは Ruby には局所変数を定義するための有標の表現―他言語でいう let, local, my―が無いせいだ(ほんとかな?)。
OCaml や Lua や Perl では何も指定せずに変数を使うということがスコープを上に辿る(ローカルになければ)ということを意味していて、局所変数とみなしたい場合にはそれぞれ明示的に let, local, my を使う。これがたぶん普通だ。Tcl のように無標の変数がローカルスコープで広いスコープに有標の表現を使う言語もあるけどいずれにせよ別の表現を割り当てている。Ruby のように表現がひとつしかなくて文脈でスコープが変わるというのが特殊なんだと思う。
ブロックの仮引数は未来のバージョンの Ruby でローカルスコープになる予定だというのをどこかで読んだんだけど、ブロックローカルな変数を導入するための表現というのも追加されるのだろうか?
2007-02-15追記: Ruby 作者のまつもと氏の先月の日記 [2] に同じ話題があった。ブロックローカルな変数を導入するための表現は導入される予定で「ブロックパラメータの後ろに「;」を置き、そこに続けた変数はブロックローカル変数」になるらしい。なんか awk みたいな…
[1] http://blog.so-net.ne.jp/rainyday/2006-10-15
[2] http://www.rubyist.net/~matz/20070112.html#p04
ブロックと関数の違い [Ruby]
今日 Ruby でブロックを使ったプログラムを書いていてはまったのだけど、ブロックの仮引数のように見えるものはブロックの外側に同名の変数がある場合はそれを参照してしまうようだ。
x="foo"
print "outside (before): " + x + "\n"
["bar"].each{|x|
print "inside block: " + x + "\n"
}
print "outside (after): " + x + "\n"
実行結果:
outside (before): foo inside block: bar outside (after): bar
一方でスコープが無いというわけでもない。
1.times{x=1}
p x
実行結果:
tryme.rb:2: undefined local variable or method `x' for main:Object (NameError)
さて、 def を使った関数定義では仮引数は当然ローカル変数になる。そして Ruby にも lambda 表記があるのだけど、これはブロックを使った表現となる。ということは def による関数定義と変数への lambda の代入は必ずしも置き換えられないということだ。
x=1
def f(x) return x end
f(2)
p x #=>"1"
f = lambda{|x| return x }
f.call(3)
p x #=>3 !!
これはややこしいなあ。というかブロックの仮引数名を決めるときに外側の変数名と衝突しないように気をつけなきゃいけないので関数型プログラミング云々以前で不便な気がする。
Ruby 雑感 [Ruby]
「たのしい Ruby」を読みながらちょっと Ruby 特有っぽいと思った部分を拾い上げて感想を書いてみます。
=== 演算子
これは「親切な比較演算子」。同値の場合に真になるのに加えて、正規表現にマッチするとかクラスに属するとか範囲に含まれるとかの場合にも真になる。これが case 構文で使われるというのがうまくはまってる感じ。
でも String === "ruby" と書けるけど "ruby" === String とは書けない。左右逆じゃないかなあ。私のセンスでは逆です。多分 === は二項演算子というより Class クラスに定義されるメソッドなのでこの順序、ということなんだと思う。
一方で /ub/ === "ruby" と "ruby" === /ub/ では前者のみ可だが、 "ruby" =~ /ub/ と /ub/ =~ "ruby" は両方許容される。これは String クラスと RegExp クラスでお互いに =~ を定義してるからかな?
あと Array に対しても定義されていればいいと思った。そうするとこれが
def space?(c)
case c
when " ", "\t", "\r", "\n"
return true
else
return false
end
end
こういう風にもかけるのに。
def space?(c)
spaces = [" ", "\t", "\r", "\n"]
case c
when spaces
return true
else
return false
end配列の集合演算
配列を集合とみなすことができる演算子 &,|,- は便利な気がした。
でも集合とみなした場合の同一性検査や正規化がないっぽいのが片手落ちだなあ、と思ったら Set クラスも別にあった。
http://www.ruby-lang.org/ja/man/?cmd=view;name=set;em=%BD%B8%B9%E7
こっちだけでいい気がします。
Integer クラスの数え上げメソッド
3.times {print "cheer, "}
みたいな書き方で繰り返しができる。これはどうだろう…
回数指定で繰り返す書き方はあると便利かとは思いますが、普通に repeat 100 {...} みたいな書き方でよかったのでは。これが数値オブジェクトのメソッドというのにはすごい違和感が。
ブロックとかイテレータがもっと Ruby っぽい部分らしいですが、それはまた後ほど。
たのしい Ruby [Ruby]
チェコ文学の翻訳などで知られる言語学者の千野栄一先生はその著書「外国語上達法」(岩波新書)でこのように書いている。
大切なことは、外国語の学習は一言語に限られているわけではないことであり、ありがたいことに何ヵ国語学習しようとかまわないことなのである。
外国語は一つしか学んではいけないというのと比べて、いくつ学んでもいいというのはなんという利点であろうか。
これはプログラミング言語にもあてはまる。よく見かける「Python と Ruby どちらを勉強したらよいか」という問題は実は問題ではない。実はなんと両方勉強したって何の問題もないのだ。しかも私見ではプログラミング言語を習得するのはチェコ語や英語を習得するのよりずっと簡単である。
というわけで Ruby 入門用に「たのしい Ruby」を買ってきました。
実をいうと私もかつて Python と Ruby どっちにしようかなと思って、そのときは Python を選択したことがあるのだ(現在の主な使い道は「Java を書きたくないが Java 用のライブラリは使いたいというときに Jython を使う」―これは Java を書きたくないすべての人にお奨め)。
同時期に第2版の邦訳がでた「プログラミング Ruby」にしなかった理由は、(1) 分冊というのが気に入らない、(2) 和書なら「やっぱり原書を読んでおけばよかったかも」などと思わずに済む、からですが、読み始めてみたらプログラミング自体の初心者向けという構成だったところがちょっと不安かも。
ether さん

-
nice! 34
記事 322
テーマ パソコン・インターネット
プロフィール
ブログを紹介する
--



